
Hi, I'm Jeremiah, the junior data engineer at JADE.
This article is part of JADE’s advent calendar for December 16th.
As a data engineer, I’m always looking to try and learn new tools to create data pipelines.
Today I'll be discussing my experience with Dagster and share my opinions on the product, including its strengths and the challenges I've encountered.
What Is Dagster?
Dagster is a cloud-native orchestrator for the entire development lifecycle. It features integrated lineage and observability, a declarative programming model, and top-notch testability. As explained on their homepage.
Its primary role is to serve as a data platform for setting up and creating data pipelines. Using its design principle of assets and ops, it intuitively shapes data served from pipelines and offers a range of features, including testing and data validation, among others.
Dagster's architecture is designed in a straightforward manner, offering complete control over deployment and data processing in a pipeline, from start to finish.
The Dagster Architecture as shown on the docs

What I’ve Liked:
Dagster's UI is great and satisfying to use. On the homepage, it clearly displays all your data assets and jobs, with the names you choose. You can group assets and jobs and organize them neatly.
Each step in a job run is clearly visible, and all your logs are in one concise place for easy debugging and data gathering.
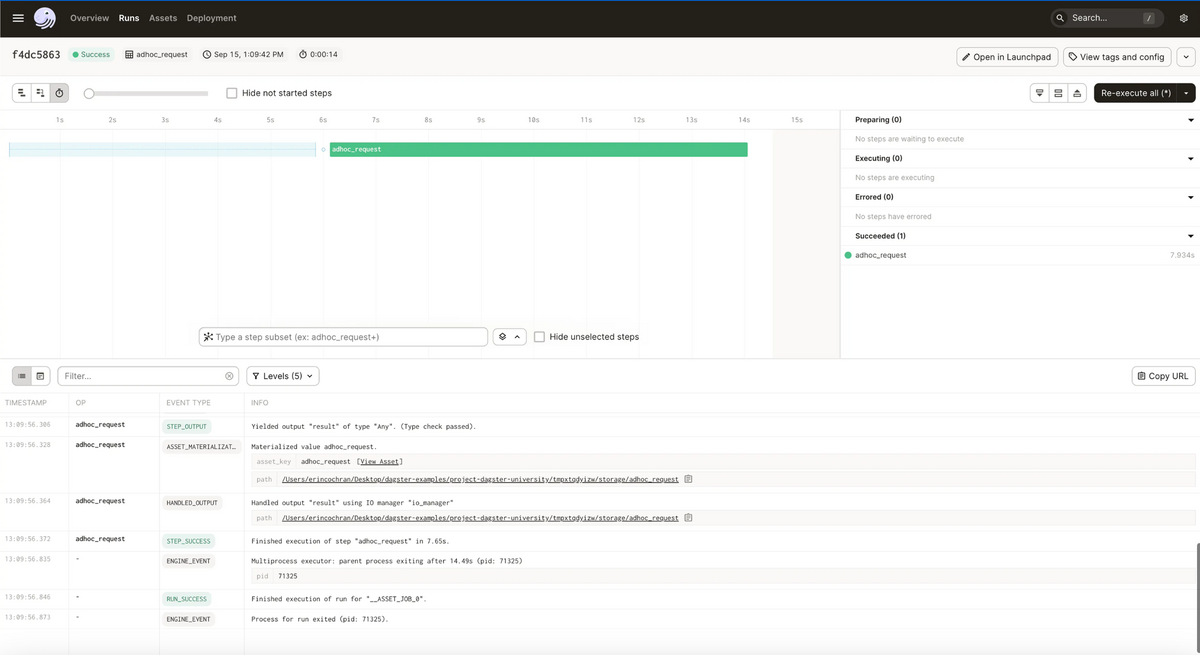
Dagster allows you to separate the development and deployment environment, making it easy to test and debug code on your local computer. This feature was particularly helpful when shipping a feature or piece of logic.
Being primarily in Python, Dagster provides access to Python's extensive libraries for working with data itself. As a data engineer, using Python feels natural and working with data in Dagster appears seamless.
Dagster also boasts an unparalleled number of features. From tests, retry policies, backfill policies, to resource and log management, everything you might want in a data pipeline can be implemented within Dagster, enhancing the detail and breadth of your data pipeline.
Challenges:
With many features comes complexity, and Dagster is no exception. Figuring out how to implement Dagster's numerous features can be challenging. It has a rather steep learning curve, which can be rewarding and grueling simultaneously. While the docs provide some tutorials and great examples, they are somewhat lacking due to the sheer number of features and situations not extensively covered. Dagster allows you to control almost every aspect of the data pipeline, but this control can also be its biggest downfall, adding a layer of complexity, especially when dealing with the deployment of Dagster itself.
Final Thoughts:
Working with Dagster has been both rewarding and challenging due to its complexity.
However, when those features and complexity become necessary, it offers strong advantages.
I'm excited for the future and look forward to seeing how Dagster evolves. They’re already improving, and recently released a free course to ease the steep learning curve.
Thank you for reading to the end of this rather long article!
Happy holidays, and stay tuned for Koriyama-san’s article tomorrow, where he'll be discussing Looker Studio Use Case Examples and Copy-Paste Functions).