
JADEファウンダーの長山です。今日は先日こちらのセミナーでも話した、「検索マーケターがBigQueryで脱初心者するにあたっての考え方」について書きたいと思います。
皆自分を初心者だと言いたい問題
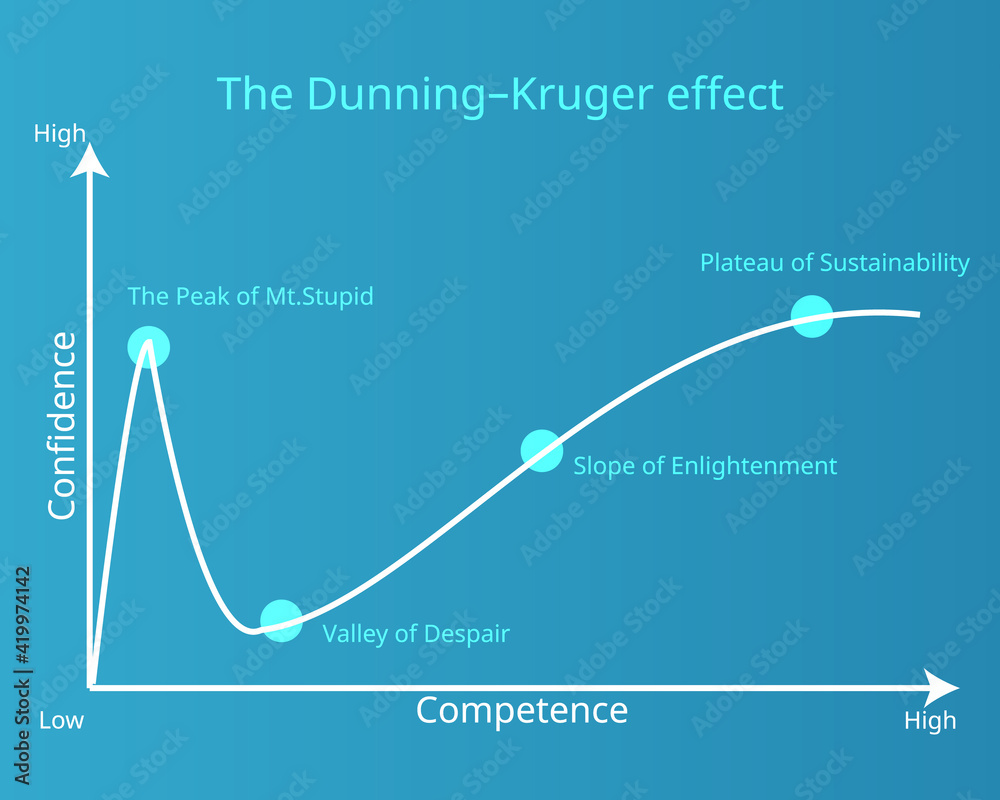
これはある程度どの分野でも存在することかもしれませんが、人によって「初心者」の定義が大きく違う問題が存在します。ダニング=クルーガー曲線における「啓蒙の坂」を上りきっていない、絶望の谷にいる人々は、本来ならすでに脱初心者しているはずなのですが、あまりに深い絶望のあまりに「何もわからない、自分は初心者だ」と思ってしまうわけです。しかし、本当の初心者は一体自分がどこまでわからなくてはならず、その中で何がわかっていないのかをうまく想像することができないはずです。「何もわからない」と言えている時点で、その人はすでに絶望の谷に降り立っており、初心者ではないのです。
また、特に BigQuery を含む SQL については、「簡単」とされる構文と「難しい」とされる構文が存在し、「どこまでSQLを理解すれば脱初心者と言っていいのか」について断絶が存在します。この点については、 Twitter (あくまで Twitter と言い続ける教に入信しています)で投票をとってみたところ、以下のような結果になりました。
【マーケターの皆さんに質問】BigQueryでのSQL、どこまで書けたら脱初心者?
— Kazushi Nagayama🕊️長山一石 (@KazushiNagayama) 2023年10月13日
これはあくまで「長山のフォロワーの中で、かつマーケターであり、この投票に応じようと思う程度には暇な人」に限定した投票なので、別に世間の大勢を代表しているわけではないのですが、その中でも4つのグループに分散しており、かついちばん多くの人が「JOIN」と答えていることがわかりました。まず、「QUALIFYが書けたら脱初心者」と答えた人は深く反省してください。仮にあなたがQUALIFYをスラスラ書けなかったとして、「俺QUALIFY書けないんだよね〜つれーわー〜」と言っている時点ですでに初心者ではありません。
じゃあどうなれば脱初心者か
では、JOIN について解説…はしません。JOIN を理解することが BigQuery 脱初心者の道だ、とは長山はどうしても思えないからです。そもそも長山が社内の初心者向けに BigQuery 101 講座をやっている感想としては、最も多くの人がまずつまづくのが集計関数と GROUP BY の使い方であり、ここを理解することで、ほとんどのすでに存在するテーブルから有意味なインサイトを引き出すことは十分に可能だと思いますので、フォーカスするべきはここです。
しかし、本稿では、GROUP BY についても深い解説はしません。そもそもSQLの構文や関数、機能について理解することがBigQuery脱初心者の道だ、というのは真実ではないと考えるからです。もちろんSQLをうまく書けるようになることは上達の中で必要な点ですし、ある関数がどのような振る舞いをするのかを理解することは最終的には必要です。けれどもそれは中級者になって、自分で関数や構文について調べることができるようになってからで十分ではないでしょうか。
マーケターにとってのSQLは、単に「今あるテーブルからアドホックな分析をする際に通らなくてはならない通過点」でしかありません。SQLというのは「道順」でしかなく、重要なのは自分がどこにいて、どこに辿りつきたいかをということです。この二つがわかっていれば、道順は自ずから明らかになってきます。SQLの書き方は Google 検索したり ChatGPT に聞いたりすることでいくらでも出てきます。けれども、どこに辿りつきたいか、については大規模言語モデルは考えてくれません。
データを知り、加工し、可視化する
マーケターがデータ分析をする、という際、ざっくり以下の工程があると思います。
- データを知る
- データを加工する
- データを可視化する
先ほどのアナロジーに擬えれば、この中で、「今どのようなデータが存在するかを知る」ということが、「自分が今いる地点を知る」ということです。そして、「どのようにデータを可視化したいかを考える」ということが、「どこへ到達したいかがわかる」ということです。SQLを書けるようになる、というのは、これらの二つが理解できた上で、「じゃあ、どうデータを加工すれば、いまあるデータを可視化したい形にできるのか」を考えられる、ということであって、データ分析の中のひとつの要素でしかありません。そして、いわゆる「初心者」に欠けているのは、この視点なのではないかと感じます。
別にSQLをスラスラ書けなくたっていいのです。リファレンスをみながら試行錯誤することができれば。もちろん試行錯誤は少ない方が上達したといえるかもしれませんが、そこは本質ではありません。僕だって一応脱初心者しているはずですが、「あれ、これってどう書くんだっけ…」と思ってリファレンスを見て新しいことを知るなんてしょっちゅうです。
データを知る
それよりもまず、データを知るために、自分が見ているテーブルのスキーマとその中身をよく観察しましょう。検索マーケターで BigQuery といえば、例えば Search Console Export のテーブルを見る機会があるかもしれません。実は Search Console Export には3つのテーブルがあって、
- ExportLogs
- searchdata_site_impression
- searchdata_url_impression
に分かれています。BigQuery の画面上で、これらのテーブルのスキーマをひとつひとつ眺めてみましょう。
- このテーブルは何のためのものか?
- このテーブルの1行は、何を表しているのか?
- このテーブルに存在するカラムは、それぞれどのような形式で、どういうデータが入っているのか?
こういった質問にスラスラ答えられるようになれば、少なくともこのデータに関しては、すでに「脱初心者」といえます。これらのテーブルは自然発生したものではなくて Google のエンジニアが作成したものですから、必ず作成者の意図があるはずです。その構造をきちんと理解すること、これがまず第一歩です。
例えばこういった質問に答えられるでしょうか。
- ExportLogs テーブル、そもそも何?
- URL テーブルと Site テーブルでどう違う?どう使い分ける?
- URL テーブルや Site テーブルに存在する sum_position って何?どう使えばいい?
テーブルのスキーマ、入っているデータ、Search Console のリファレンスをみながら、上の質問に答えられるかやってみましょう。
データを可視化する
上記の質問に答えられるようになったら、このデータを使って何が可能なのか、についての想像力がついてくると思います。例えば、このデータはあくまで検索に関するものなので、ユーザーがサイト内にランディングしてからの行動については見ることができません。そこで、以下のようなケースを考えてみます。
- 指名クエリなど、クエリの種類ごとに
- Web 検索で
- impression の推移を
- まとめて見たい
結構具体的なケースですが、こういったニーズは、検索に関わるマーケターにとってはよくあるもののはずです。
では、これをやるとしたらどういったグラフになるでしょうか。おそらく、日付に対して impression をプロットして、複数の線がそこに書かれているような、線グラフが適切でしょう。ということは、必要なのは、どういうデータでしょうか?考えてみると、
| date | query_type | impressions |
|---|---|---|
| 2023-10-21 | 指名 | 367 |
| 2023-10-21 | 非指名 | 2543 |
| 2023-10-22 | 指名 | 338 |
| 2023-10-22 | 非指名 | 3677 |
| 2023-10-23 | 指名 | 363 |
| 2023-10-23 | 非指名 | 4931 |
こういったテーブルがあれば、線グラフができそうです。
データを加工する
では、自分が今持っているデータから、上のテーブルを導き出すためには、どのような加工が必要でしょうか。このステージに来て初めて、SQLが登場します。
例えば上のアンケートで出てきたものを使うとしたら、どれを利用することになるでしょうか。
- WHERE
- 集計関数 + GROUP BY
- JOIN
- WINDOW
こうやってアルファベットで書くとなんとなく難しそうに見えるかもしれませんが、要はこういうことですよね。
- WHERE = データをフィルタして絞り込みたい
- GROUP BY = 行を跨いで集計したい
- JOIN = テーブルをくっつけたい
- WINDOW = 集計結果を行ごとに出したい
こう考えると、現在やりたいことは
- Web 検索に絞り込みたい
- 日付ごと、クエリの種類ごとに impression を集計したい
ということなので、利用するのは WHERE と GROUP BY だな、ということになります。
上でも言いましたが、マーケターのユースケースの大半では、GROUP BY がきちんと書ければ十分です。むしろ、マーケターなのに JOIN を駆使してゴリゴリやらないといけない、という状況は何かがおかしいはずです。エンジニアが必要なのにいないとか、必要なリソースが適切に割かれていないとか…文句を言っていい状況だと思います。
それでは、WHERE と GROUP BY を利用して上の二つを実現するためにはどうすればいいかを考えましょう。
- Web 検索に絞り込む、ということは、
WHERE search_type = 'web' - 日付とクエリの種類ごとに集計したい、ということは、
GROUP BY data_date, query_group
と考えられます。つまり、こんな感じですね。
SELECT
date, query_type,
SUM(impressions) AS imps
FROM site_table
GROUP BY date, query_type
しかし、ここで問題です!もともとの Search Console Export のテーブルの中には、 query_type がありません。 クエリそのものの文字列を入っているけれども、そのクエリをどういう風に分類するかと言う情報は、もともとのテーブルの中には入っていないわけです。ですから、その情報をSQLを利用して作ってあげる必要があります。 BigQueryのリファレンスを見ながら、どういう風にこのクエリ分類情報を作ればいいか自分でも考えてみましょう。
答えを言ってしまうと、こういう時に活躍するのが CASE 文です。
CASE
WHEN query LIKE ‘%jade%’ THEN ‘指名’
ELSE ‘非指名’
END
これを使えば、ある条件が満たされたのであればX、別の条件が満たされたらY、のような分類を作っていくことができます。よかったですね!
ついでなので、 他の指名クエリのパターンも対応できるようにしてみましょう。
SELECT
data_date AS date,
CASE WHEN LOWER(query) LIKE '%jade%'
OR query LIKE '%ジェイド%'
OR query LIKE '%じぇいど%'
THEN '指名'
ELSE '非指名' END AS query_type,
SUM(impressions) AS imps
FROM `myproject.searchconsole.searchdata_site_impression`
GROUP BY date, query_type
ORDER BY date DESC, query_type DESC
こうすることで、
- 大文字・小文字のアルファベット
- カタカナ
- ひらがな
に対応することができました。
これをビューとして保存して、
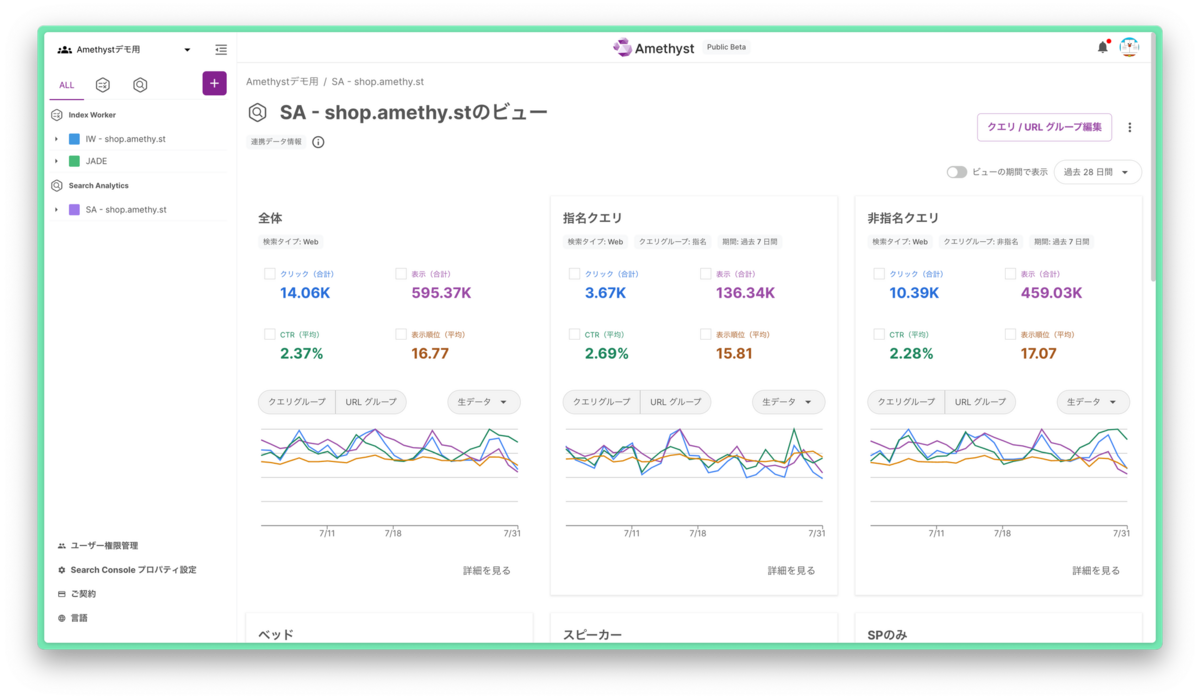
Looker Studio で可視化したものがこちらです。
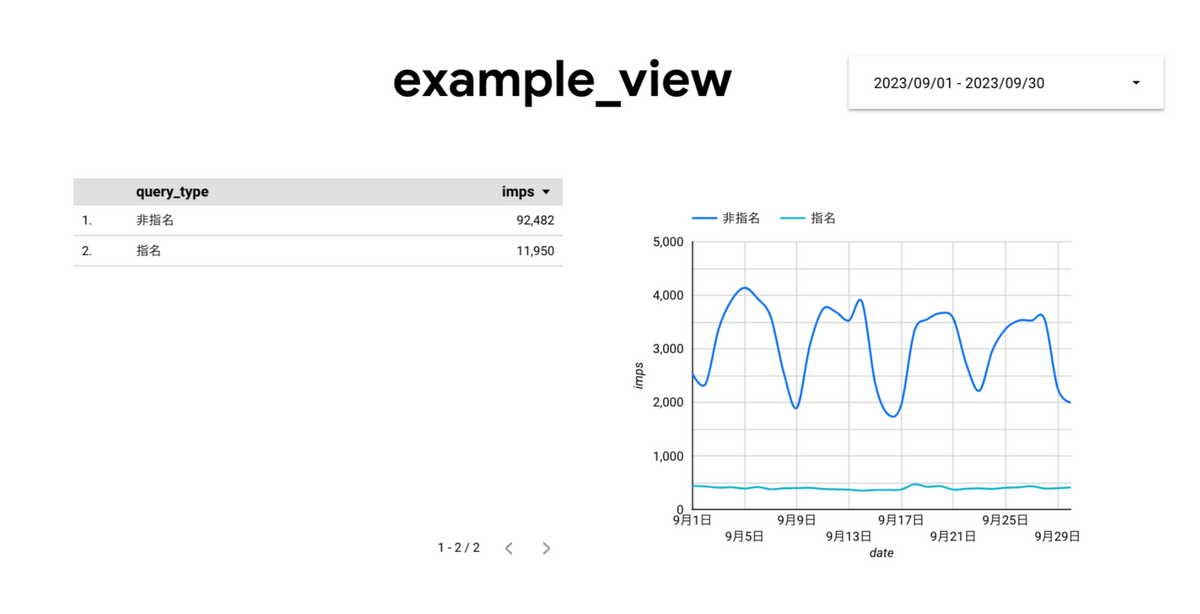
指名・非指名の推移をいい感じで見ることができるようになりました。指名は一定だが、非指名は平日は流入が上がるようなパターンがあることがわかります。
SQL が書ける、ということが本質ではない
Search Console の BigQuery Export データを使って、どのようにデータを可視化するかというシナリオをひとつ検討してみました。 当たり前の事なのですが、SQLが最初にあるわけではなく、どのような分析をしたいのか、どのようなデータの可視化が行いたいのかがあって、初めてどのようなSQLを書くべきかということがわかってきます。 脱初心者するためにむしろ重要なのは、どのようなデータが存在し、そこからどのようなデータの可視化が可能かということを具体的なイメージを持って理解することであって、それをどのようにSQLを用いて行うか、と言うのは実はその次に出てくる話だということがわかります。
今どこにいるのか、を把握し、どこへ辿りつきたいか、が明確にできる人。それが重要なのです。
さて、ここで宣伝です
「どこへ辿りつかいたいか」がわかっても、SQLでそれを実現するのは意外と大変です。いろいろ試行錯誤をしないといけないし、自分が書いている文が正しいのかを確認しないといけない。ChatGPTに書いてもらったとしても、それが本当に正しいSQLなのか、ちゃんと動作するのかを見るのは人間の仕事です。大変ですね。
そこで JADE では、「SEOに必要なモニタリングやアドホック分析を、高速にかつ大量に行う」ことを前提に、Amethyst という SaaS を作りました。Search Console BigQuery Export をゴリゴリ叩いて、高速に色々な分析を行いたい、という方向けのツールです。それに加えて、特定の条件下のURLがどれくらいクロール・インデックスされているか、canonical はどのような状況か、など、インデックス周りの分析がサクサクできる機能もついています。
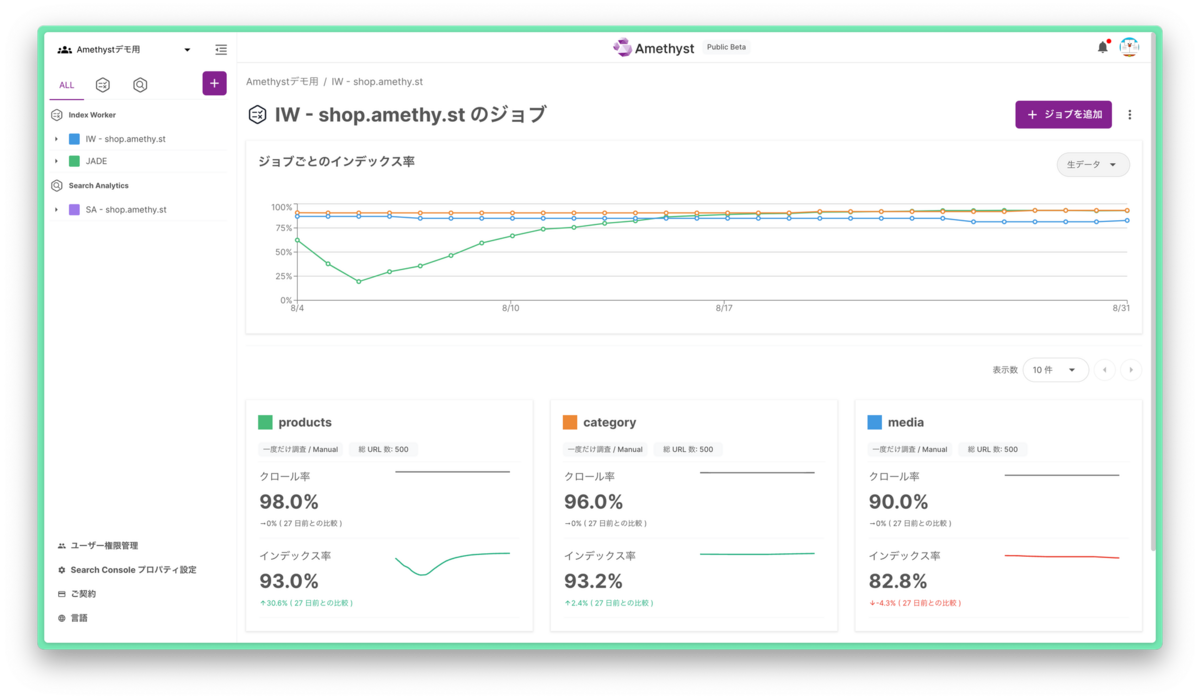
JADEのコンサルタント諸氏からは「もうこれなしでは業務を行えない」などの声が届いており、大変好評です。現在はパブリックベータ期間中で、なんと今年中に申し込んでいただければ1年契約で6ヶ月無料で使えます。通常のチームプランの価格は月額39,600円なので、めちゃくちゃオトクです。ぜひご活用ください!興味のある方はぜひ以下のページからお問い合わせをお願いします。