

SEOを考えたWebサイトの運営を行う上で、Search Console 内の1つの機能である検索パフォーマンス レポートで確認できるデータを活用しないという選択肢はありません。
検索パフォーマンス レポートでは、Search Console で設定した自身の関わるWebサイトのプロパティ範囲内という制約こそありますが、Google 検索を利用した検索ユーザーのGoogle 検索結果ページ上での行動データを確認することができるためです。
上記での行動データというのは、Google 検索で検索したユーザーが「どのような検索キーワード」で検索して、検索結果に表示された自身の関わるWebサイトの「どのページ」をクリックし、サイト内へ流入しコンテンツを閲覧することになったのかをデータを指します。
Webサイトをより良くするためのSEOを考えた改善施策に必要不可欠となる行動データを確認できるSearch Console の検索パフォーマンス レポートですが、Google 社はGoogle 検索を利用した検索ユーザーの行動データをすべて提供しているわけではありません。
一部のデータを除外した後の欠損した行動データをSearch Console の利用ユーザーに提供しています。
ですので、私たちSearch Console の利用ユーザーは、欠損したデータからインサイトを読み解き、改善施策に繋げていかなければいけません。
では、どのようなデータが一部のデータとして除外されているのか、除外された後のデータがどのように集計され、Search Console の利用ユーザーに提供しているのか。データの取扱方法を知っておくことは、データを正しく活用していく非常に重要なポイントとなります。
結論として、Search Console の検索パフォーマンス レポートにおけるデータが不完全になってしまうのは、下記のような理由があげられます。
- プライバシー保護のための検索キーワードデータの欠損
- Search Console のUI上での1,000URLを上限とした表示制限
- データポータルを利用した場合、1日あたり5,000URL以上のデータは表示されない切り捨て
- データポータルを利用した場合、1日あたり5,000キーワード以上のデータは表示されない切り捨て
- データポータルを利用した場合、ページURLとキーワードの組み合わせ種類数50,000以上のデータは表示されない切り捨て
私は調査した結果、上記のようなデータ制限を確認しました。
この記事では、JADE社で確認できる様々なWebサイトにおけるSearch Console の検索パフォーマンス レポートで集計されているデータを調査し、Search Console のデータがどのような条件で欠損しているか、そしてWebマーケターがどのようにこの問題と向き合うべきかを解説します。
検索パフォーマンス レポートで一部除外されるデータとは
まず、私たちが利用する検索パフォーマンス レポートで、どのようなデータが一部除外される可能性があるのか、ヘルプページより確認してみます。
検索パフォーマンス レポートにはデータが一部除外される要因として以下の説明がヘルプページに記載されています。
以下、ヘルプページ内の該当部分からの参照です。
グラフの合計と表の合計の不一致
次のような理由により、グラフの合計と表の合計が異なる場合があります。
全般:
- ページやクエリでフィルタした場合の「一致」と「不一致」の合計が、フィルタしない場合の合計よりも少なくなることがあります。たとえば、「次を含むクエリ: マウス」と「次を含まないクエリ: マウス」の合計を加算しても、クエリでフィルタしなかった場合の合計と同じにならないことがあります。これは、匿名化されたクエリが除外されたり、表示制限によりデータが切り捨てられたりするためです。
- まれに、ページやクエリでフィルタすると、グラフと表でデータに差異が生じることがあります。これは、グループ化とフィルタリングの組み合わせによって、データの切り捨てが異なるためです。このようなケースで合計が異なる場合、実際の合計は少なくとも表示されている大きな方の値(それ以上のこともある)になります。
- サイトのルート URL「example.com/」の結果に対するフィルタリングなど、無効なフィルタを追加すると、さまざまな理由で不一致が生じることがあります。
グラフの合計の方が大きい:
- 表には 1,000 行までしか表示されないため、一部の行が省略される可能性があります。
- クエリごとの表示では、匿名化された結果(非常にまれな結果)は表から除外されます。
- 1 日ごとの合計では、まれなクエリが省略される場合があります。
表の合計の方が大きい:
- 表をページや検索での見え方でグループ化すると、表の合計は URL ごとにグループ化されますが、グラフの合計は引き続きプロパティごとにグループ化されます。そのため、1 回の検索で 1 つのプロパティが複数回表示された場合、グラフでは表示回数 1 回としてカウントされますが、表では複数回カウントされます。
- 検索での見え方の一部のタイプは、他のサブカテゴリです。たとえば、求人の一覧はリッチリザルトのサブカテゴリであるため、同じ結果が両方の行に表示されます。
上記のヘルプページに記載されている内容をまとめると、主に以下の2点が一部除外されるデータの対象として想定されます。
- 検索キーワード (Query) では、データが一部除外される
- データセットによってデータのレコード上限が存在する
上記、2つのデータが除外される集計仕様が存在しますが、サイト規模によって2つとも適用されるケースと、1つしか適用されないケースが存在すると考えられます。その理由を以下に記載します。
まず、1.に関しては個人ブログ、コーポレートサイトやスモールビジネスを展開する小規模なサイトなども含む、すべてのWebサイトが適用されると想定されます。
Google社が除外する検索キーワードを決定し、データとして利用ユーザーに提供しているためです。データとして提供しないと決定した検索キーワードはブラックボックスであるため、私たちSearch Console の利用ユーザーは知るよしもありません。
そのため、検索キーワードがどのようなプロパティ、どのようなページにて一部除外されているのか、フィルタで検索キーワードをフィルタリングした際は、どのようにデータが絞り込まれるのか理解し、データとして活用するように気をつける必要があります。
簡単に確認する方法としては以下のような手法があります。
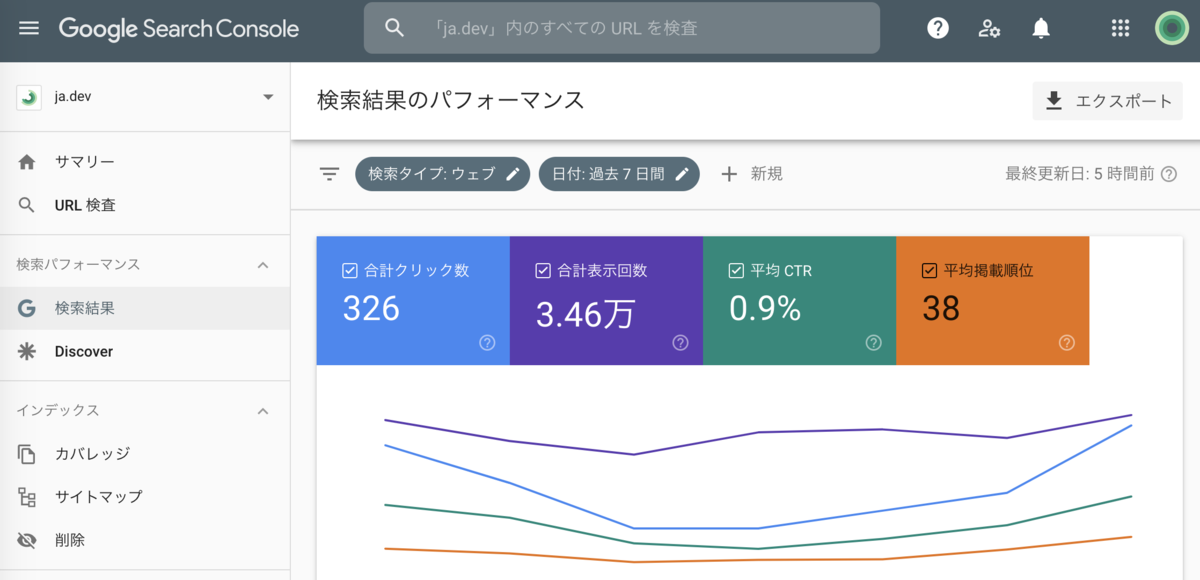
まず、レポートUIにて日付以外のフィルタリングが適用されていないデータを確認します。
下記の期間ではクリック数が326であることがわかります。
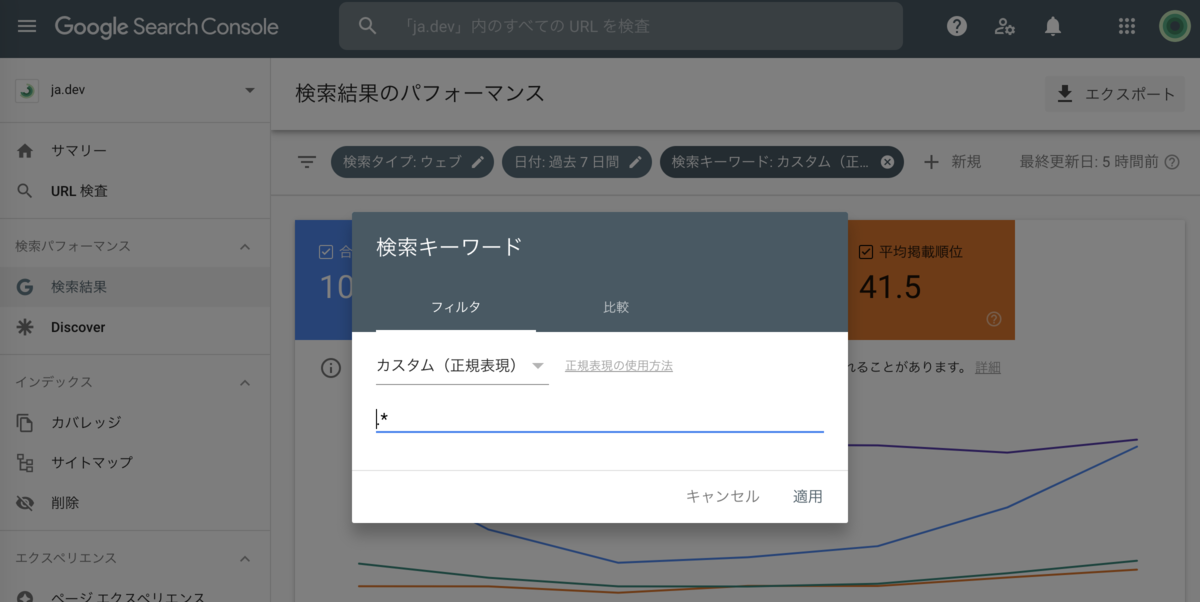
検索キーワードでフィルタリングします。正規表現で”.*”と入力し、適用します。
正規表現で”.*”は0以上の任意の文字列となり、Search Console の検索パフォーマンス レポートで検索キーワードに対して利用すると、すべての検索キーワードを対象にデータを抽出することができます。
上記の条件でデータを抽出すると、下記のようにクリック数が101へ減少しました。
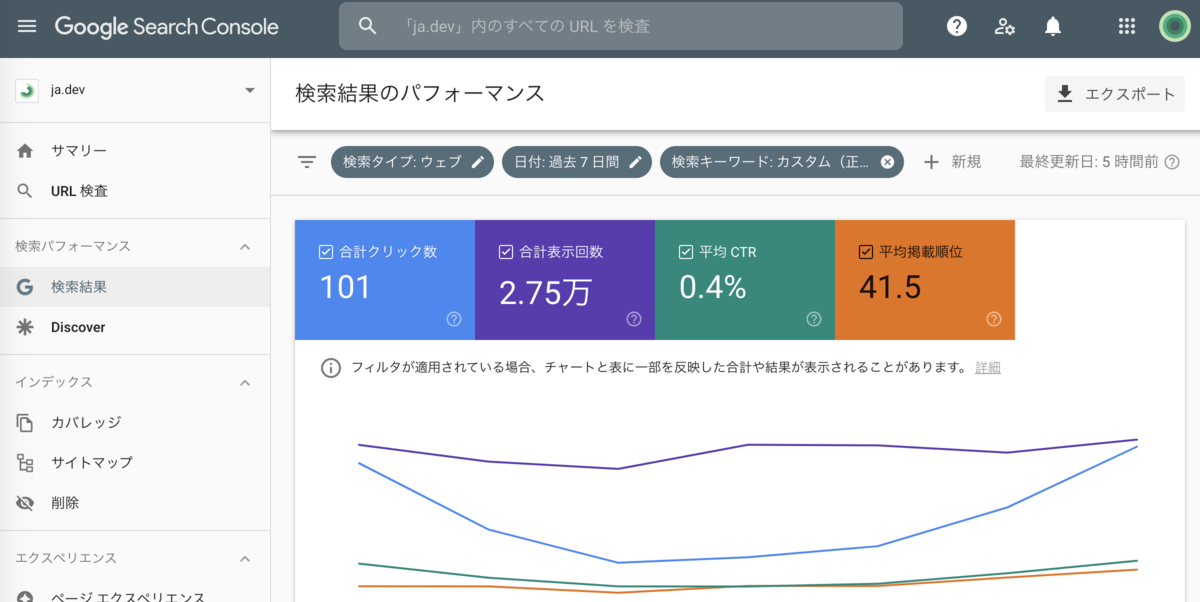
つまり、検索キーワードとしてデータが集計されているクリック数を合計すると101しか存在しないことになります。
一方で、2.に関しては大規模サイトなど、Google 検索の検索結果に表示される Web サイト内の URLユニーク種類数が多く存在するほど、切り捨てとなるページが増加してしまいます。
そのため、自身が運営しているWebサイトでSearch Console に設定しているプロパティごとに、どの程度のレコード上限による切り捨てが発生しているのか確認しておきましょう。
特に切り捨てられているデータの範囲が大きい場合は特に注意が必要となります。
簡単に確認する方法としては以下のような手法があります。
まず、レポートUIにてクリック数が降順にデータが掲載されています。
それを下記のようにオレンジ矢印の「クリック数」と記載された部分をクリックすることで降順から昇順へ変更します。
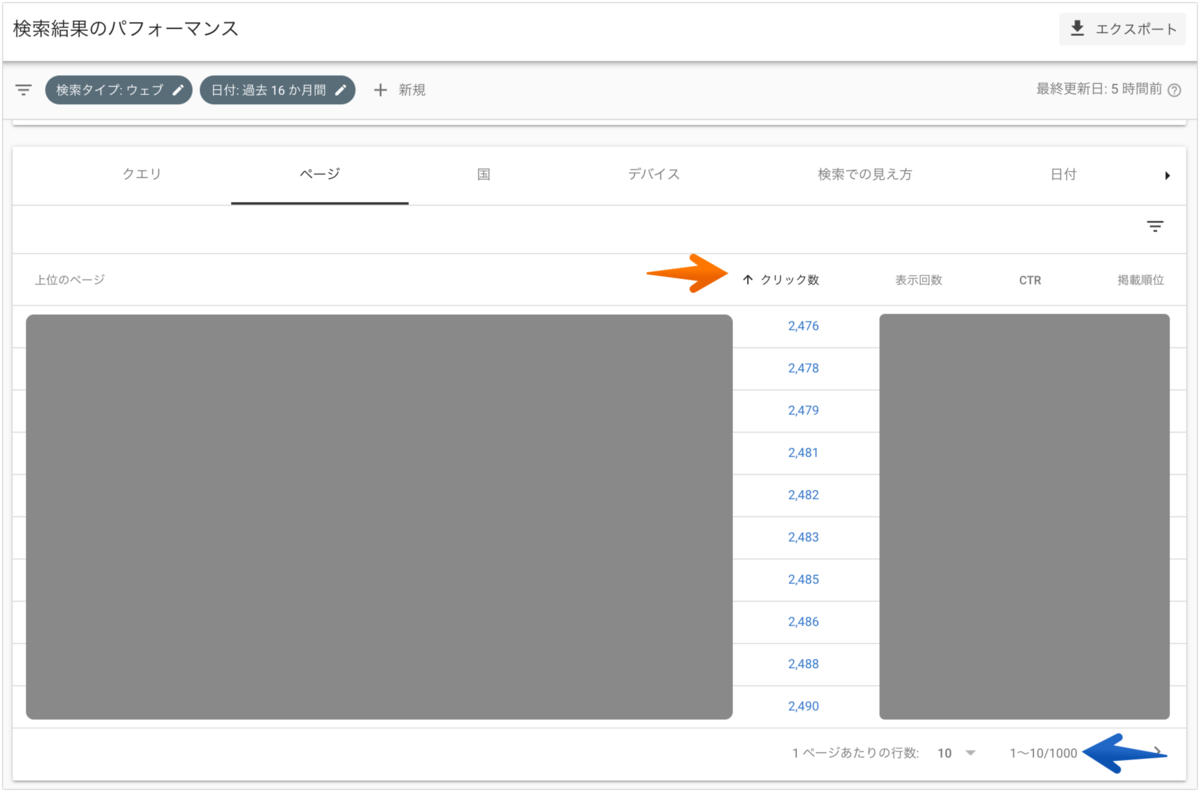
1番上のレコードはクリック数が2,476であることがわかります。
青矢印部分から確認できるようにレコード数は1,000行となります。クリック数を昇順で表示しているため、クリック数が2,476以下のページにおけるクリック数は切り捨てとして扱われています。
フィルタを利用しないと、1,001行目以降に集計されたページのクリック数を確認することができません。しかし、後述しますがフィルタを利用したとしても、プロパティ内のレコード上限による一部データ除外のためフィルタ抽出不可能なページも存在してしまいます。
そのため、いかにプロパティ内でレコード上限に達しないような構成でプロパティを作成するのかが重要となります。
以下、調査して確認することができた、それぞれのデータ集計仕様を記載します。
1.検索キーワード (クエリ) ではデータが一部除外される
Search Console の検索パフォーマンス レポートで利用できる検索キーワードである「クエリ」では、匿名化されていないクエリ文字列のみが表示されます。
検索パフォーマンス レポートのヘルプページ内「ディメンションとフィルタ」には以下の説明が記載されています。
検索パフォーマンス レポート - Search Console ヘルプ
https://support.google.com/webmasters/answer/7576553?hl=ja#zippy=%2C%E3%82%AF%E3%82%A8%E3%83%AA
クエリ
ユーザーが Google で検索したクエリ文字列です。サイトから返された匿名化されていないクエリ文字列のみが表示されます。
匿名化されたクエリ
匿名化されたクエリと呼ばれる非常にまれなクエリは、ユーザーのプライバシーを保護するために結果に表示されません。匿名化されたクエリは、常に表から除外されます。匿名化されたクエリは、クエリ(特定の文字列を含むクエリまたは特定の文字列を含まないクエリ)でフィルタしない限り、グラフの合計数に含まれます。
匿名化されたクエリが多いサイトでは、グラフの合計数と、「次を含むクエリ: 特定の文字列」を適用した場合の合計数と「次を含まないクエリ: 特定の文字列」を適用した場合の合計数を足した数に大きな差が生じることがあります。これは、フィルタが適用されると、匿名化されたクエリが除外されるためです。
また、同ページ内の「データの不一致」には以下の説明が記載されています。
グラフの合計と表の合計の不一致
次のような理由により、グラフの合計と表の合計が異なる場合があります。
全般:
- ページやクエリでフィルタした場合の「一致」と「不一致」の合計が、フィルタしない場合の合計よりも少なくなることがあります。たとえば、「次を含むクエリ: マウス」と「次を含まないクエリ: マウス」の合計を加算しても、クエリでフィルタしなかった場合の合計と同じにならないことがあります。これは、匿名化されたクエリが除外されたり、表示制限によりデータが切り捨てられたりするためです。
(中略)
グラフの合計の方が大きい:
- 表には 1,000 行までしか表示されないため、一部の行が省略される可能性があります。
- クエリごとの表示では、匿名化された結果(非常にまれな結果)は表から除外されます。
- 1 日ごとの合計では、まれなクエリが省略される場合があります。
ヘルプページに記載されている上記の部分から、Search Console の利用ユーザーには Google 検索の検索結果における検索キーワードのデータがすべて提供されているわけではないと読み取れます。何らかのロジックによってデータが一部除外された後の検索キーワードに関するデータが提供されていると理解できます。
では、気になる点として「実際にどの程度データが除外されているのか?」が頭に浮かび上がります。
そのため、Search Console の様々なプロパティにおけるデータを調査してみました。
すると、驚きの調査結果となりました。結果概要ですが、Search Console に設定しているプロパティによって、一部除外されているデータの量が異なっていました。
なお、調査方法は以下のような方法で行いました。
もし、ご自身のSearch Console で確認される際は参考にしてみてください。
データポータルにて下記のような2つの表を作成します。
1つが表に検索キーワードである Queryを含まないもの。もう1つが表に検索キーワードである Queryを含むものとなります。
検索キーワードである Query がディメンションに追加されることで、1つのページに対して、どの程度のデータの一部除外が発生しているのか確認しました。
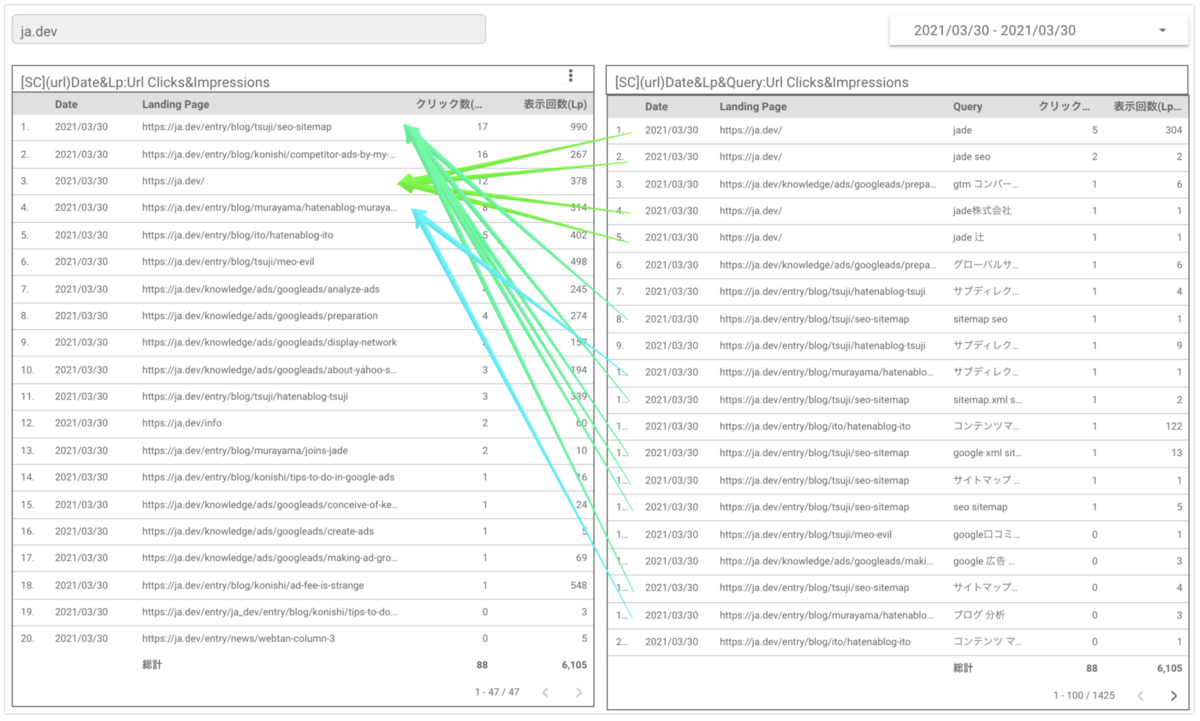
上記のデータポータルは以下のディメンション、指標を設定しています。
・左の表
ディメンション:「Date」(日付)、「Landing Page」(ページ)
指標:「Url Clicks」(クリック数)、「Impressions」(表示回数)
・右の表
ディメンション:「Date」(日付)、「Landing Page」(ページ)、「Query」(検索キーワード)
指標:「Url Clicks」(クリック数)、「Impressions」(表示回数)
それぞれの表からデータをエクスポートし、左の表にある「Date」(日付)と「Landing Page」(ページ)をキーに、右の表にある「Date」(日付)と「Landing Page」(ページ)をLEFT JOINすることで、「Landing Page」(ページ)ごとに左の表と右の表にそれぞれ抽出した指標である「Url Clicks」(クリック数)や「Impressions」(表示回数)の数値差分を確認しています。
数値差分を調査した際のアウトプットイメージは下記のようなデータとなります。
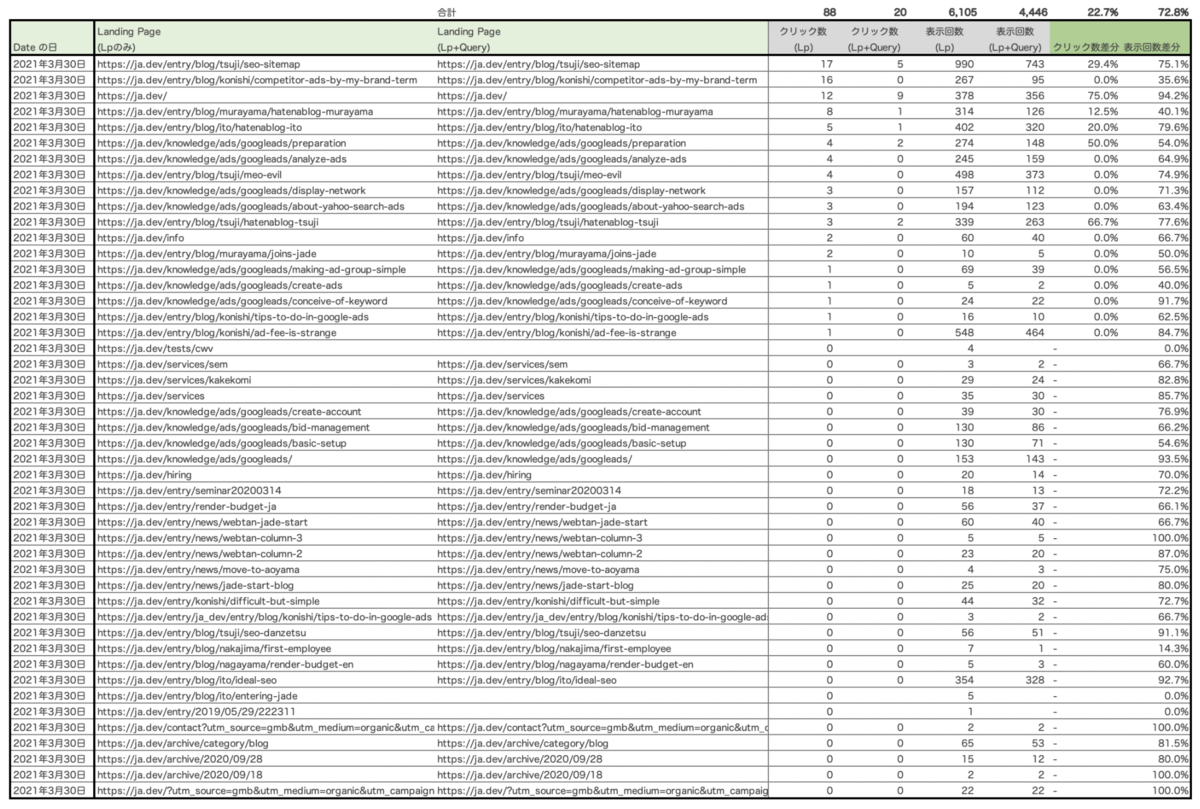
ディメンションに「Date」(日付)、「Landing Page」(ページ)が設定された場合のクリック数、表示回数と、「Date」(日付)、「Landing Page」(ページ)、「Query」(検索キーワード)が設定された場合のクリック数と表示回数に差分があるのが確認できます。
弊社のWebサイトのような小規模なサイトだと上記のように、特定の日付における数値の乖離は大きい傾向がありました。
一方で、Webサイト内の更新性が高く、サイト内に大量のページがあるような大規模サイトのプロパティでは、両データ間のクリック数には約50〜80%の数値の乖離が見られました。
なお、同じWebサイトでも Search Console のプロパティが異なっても、数値の乖離は同じでした。
例えば、以下のイメージのようにWebサイトAに対して、ドメインプロパティのSearch Console プロパティAとURLプレフィックスプロパティの Search Console プロパティBという構成とします。
ドメインプロパティではURLプレフィックスプロパティで計測している対象のディレクトリである/Sample/をページフィルタで設定し、ドメインプロパティでもURLプレフィックスと同じページが抽出できるようにフィルタリングします。
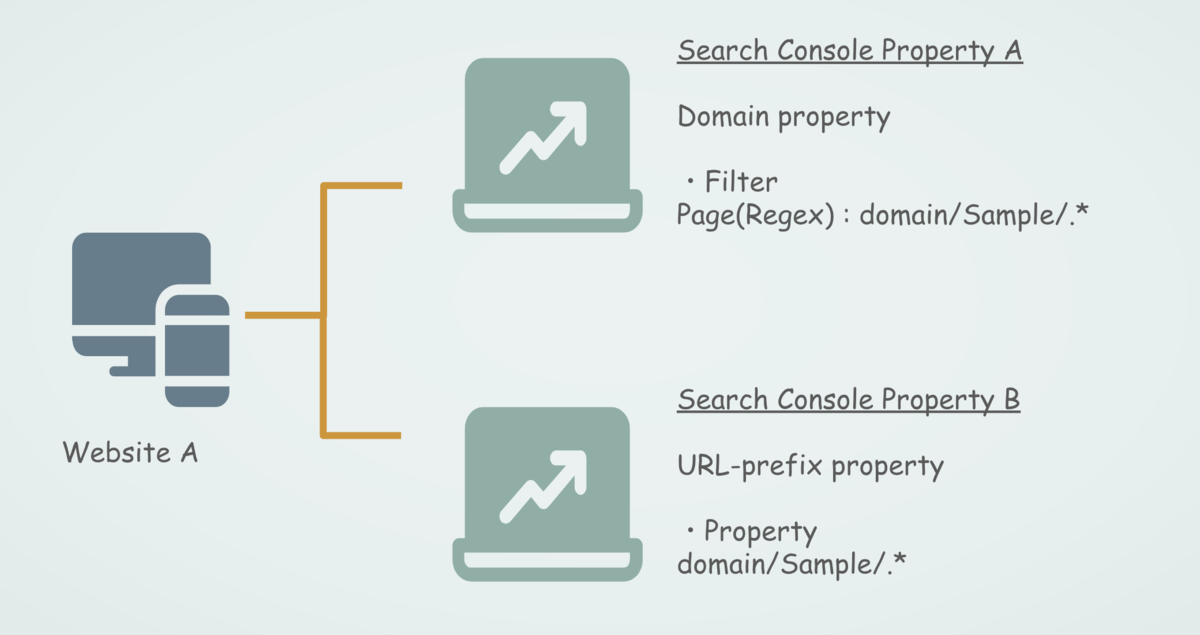
ドメインプロパティで/Sample/ディレクトリ以下を抽出したデータと、/Sample/ディレクトリ以下を対象に作成したURLプレフィックスプロパティのそれぞれのデータで、前述のクリック数、表示回数の数値差分調査を行ったところ、それぞれのデータで同じ数値の乖離が見られました。
しかし、同じWebサイトでも異なるディレクトリを対象に作成したプロパティ間では、数値の乖離幅は異なりました。
例えば、以下のように/Sample/ディレクトリを対象に作成した Search Console プロパティBと、/hogehoge/ディレクトリを対象に作成した Search Console プロパティCが存在するとします。

上記の Search Console プロパティBと Search Console プロパティCで、クリック数、表示回数の数値差分調査を行いました。
すると、 Search Console プロパティBでは数値の乖離が約55%で、一方の Search Console プロパティCでは数値の乖離が約 70% でした。その Web サイトではその他のディレクトリにおいてもSearch Console の他プロパティとして用意されていたため、それぞれで調査しましたが、50%台〜70%台と異なる数値の乖離幅でした。
以上までの調査結果から、検索キーワードであるQueryにおけるデータ一部除外は、ページごとに発生していると想定することができます。
ディレクトリや重要なページごとに、どの程度の割合でデータの一部除外が発生しておきましょう。特定の検索キーワードにおけるクリック数などをKPIとして設定しているケース等では、一部除外されるデータの割合次第でKPIの見直しが必要かもしれません。
その他で、Search Console のレポートUIで指名検索率を確認しているケースでも注意した方がよいでしょう。ヘルプページにも記載されていますが、匿名化されたクエリとして一部除外されたデータを指名検索率の計算にカウントしないことが望まれます。
検索パフォーマンス レポート - Search Console ヘルプ
https://support.google.com/webmasters/answer/7576553?hl=ja#zippy=%2C%E3%82%AF%E3%82%A8%E3%83%AA
・ブランドクエリや非ブランドクエリの合計を探す。
検索結果にサイトが表示されたクエリについて、ブランド名など特定の文字列を含むもの、含まないものの数を確認できます。匿名化されたクエリはカウントされず、クエリでフィルタするとロングテール データが失われる可能性があるため、あくまで近似値ですが、ブランドクエリの割合はおおまかに次の式で求められます。

匿名化されたクエリとして一部除外されたデータを指名検索率の計算にカウントしない手法として以下の手法が考えられます。
まず、指名検索にあたる検索キーワードをフィルタリングし、指名検索した際のデータを抽出します。
(先日、レポートUIでフィルタリングに正規表現を使えるようになったのは非常に便利ですね!)
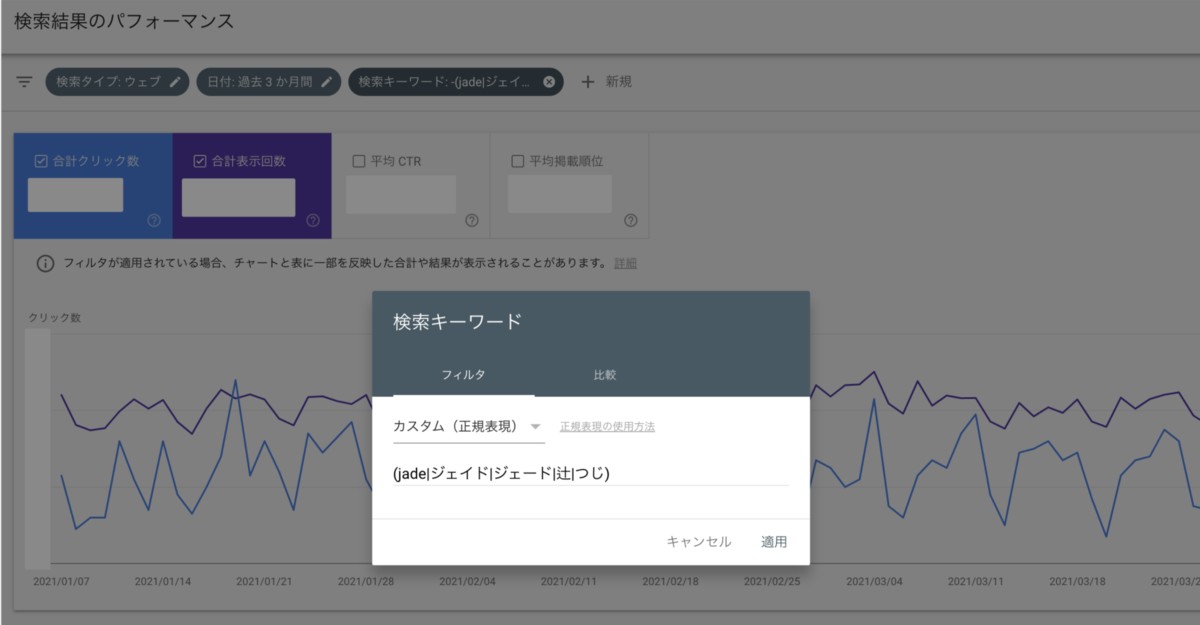
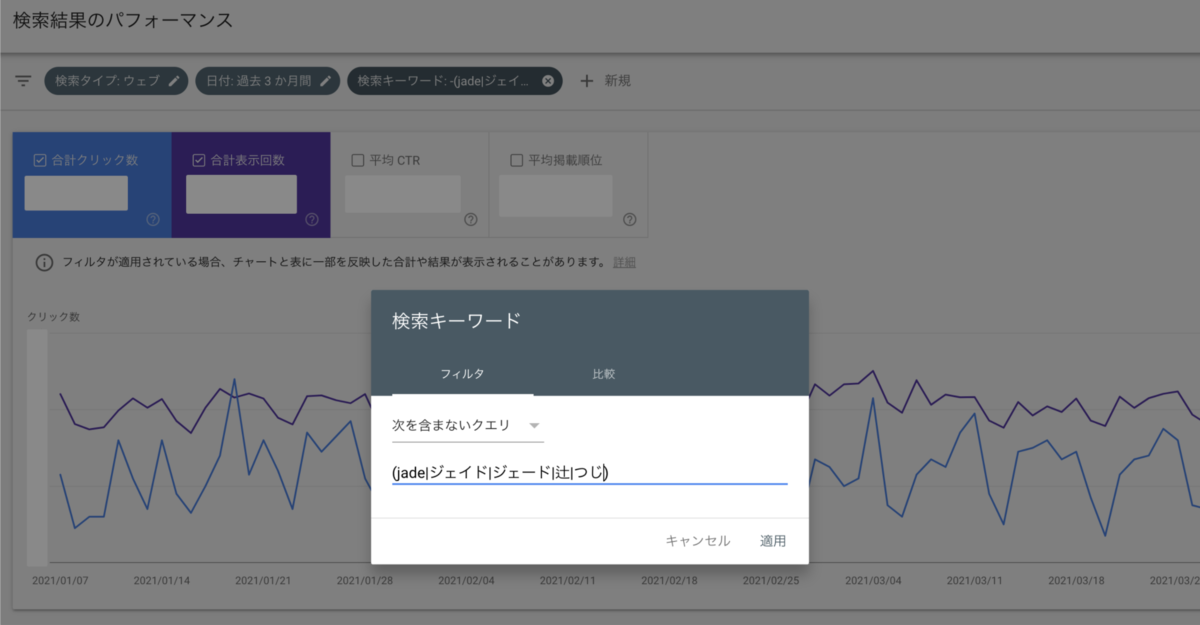
その後、検索キーワードとしてデータ集計されていない検索キーワードに対して、「次を含まないクエリ」としてデータを抽出します。
下記の例では、正規表現での抽出を行うために入力した文字列をそのまま、正規表現が適用されない「次を含まないクエリ」の条件として指定しています。正規表現での抽出を行うために入力した文字列で、Google 検索を行うユーザーは存在しないと想定されるためとなります。
(レポートUIのフィルタリングで「正規表現にマッチしたデータを除外」も利用できるようになるといいですね…)
前者のデータを後者のデータで割り算することで、指名検索によるサイト内流入率を近似値ではありますが算出することができると想定されます。

もし、特定のディレクトリ(もしくはページ)ごとに指名検索によるサイト内流入率を算出する場合は、対象となる特定のディレクトリで設定しているURLプレフィックスプロパティを利用するか、もしくは「ページ」によるフィルタリングを併用してデータを抽出するようにしましょう。
2.データセットによってデータのレコード上限が存在する
Search Console の検索パフォーマンス レポートでは、データを抽出する際のデータセットであるデータセットが存在します。
データセットは、検索パフォーマンス レポートのデータをエクスポートしたスプレッドシート、ExcelやCSV内のシートが分かれていることからわかるように、日付、国、デバイス、クエリやページによって、それぞれのデータセットが存在すると想定されます。
データを確認、エクスポートする際に、データセットごとにデータを参照し、そのデータセットごとにデータのレコード上限が存在するようです。特にデータのエクスポート方法によってレコード上限が異なるため注意が必要となります。
Search Console のデータは、大きく分けて2種類のデータエクスポート方法が存在します。1つは Search Console のUI画面からデータをエクスポートする方法と、もう1つはデータポータルでのSearch Consoleコネクタ を利用したデータのエクスポート方法となります。なお、Search Console のAPI を利用したデータ取得は、今回のデータエクスポート方法には含まれておりません。
それぞれのデータエクスポート方法によって、取得できるデータのデータセットにおけるデータのレコード上限数が異なるため、それぞれ下記に記載します。
Search Console UI 画面からエクスポートするデータのレコード上限
Search Console では画面右上の「エクスポート」より、検索パフォーマンス レポートのデータをエクスポートすることができます。
Search Console UI からエクスポートする際、データのレコード上限数は1,000行となります。16ヶ月分のデータエクスポートしかできない「日付」、デバイス種類が限られる「デバイス」、世界中の国や地域の種類が限られる「国」はユニーク種類数が1,000種類を超過することがないため問題ありません。
しかし、Google 検索で検索された検索キーワードである「クエリ」や、Webサイト内のURLである「ページ」はサイト規模によってはユニーク種類数が1,000種類を超過する可能性が高く、レコード上限数である1,000行内にデータが収まらない可能性があるため注意する必要があります。
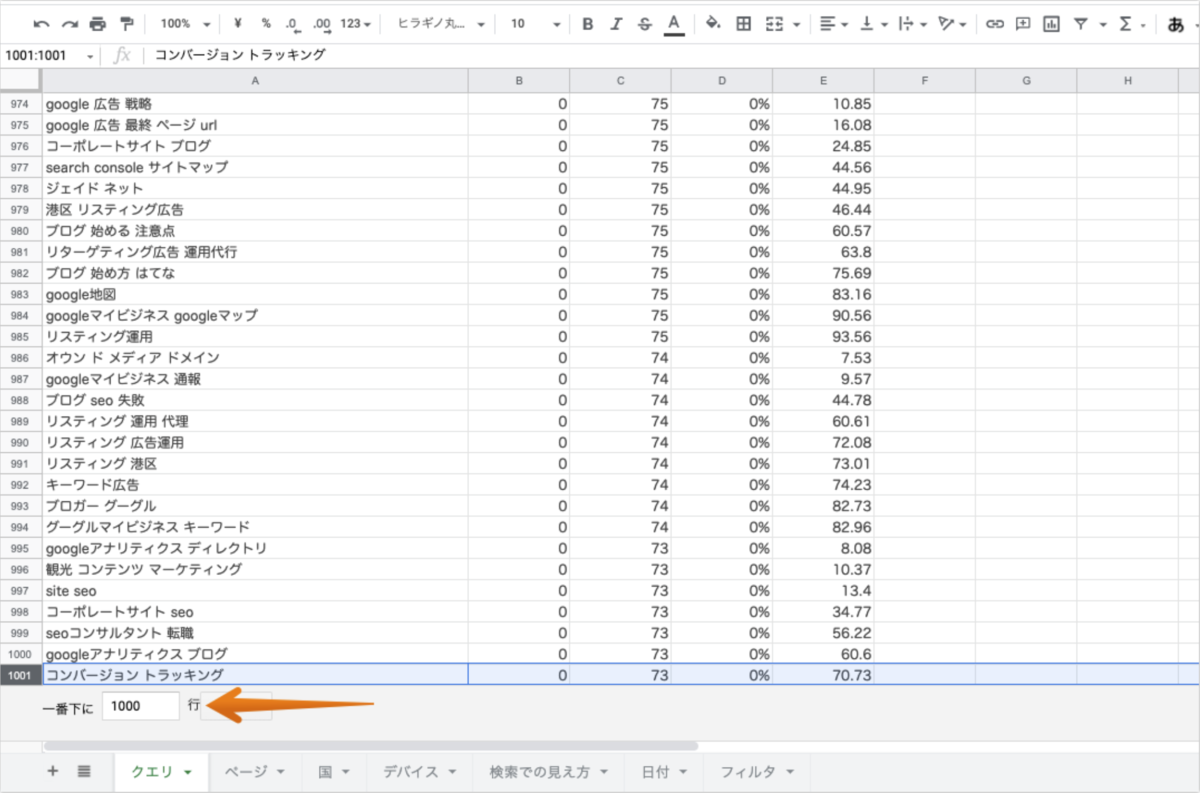
また、エクスポートできるデータにも集計仕様が存在します。
1,000行までのレコードしかエクスポートすることができない中、データの表示順序として第1ソートがクリック数、第2ソートが表示回数の降順で1,000行までのデータをエクスポートすることができます。
そのため上記のように、クリック数が0の検索キーワードの中でも、表示回数が73以下の検索キーワードは途中から一部除外されたデータとなってしまいます。
上記のようにクリック数が0の検索キーワードにてデータが欠損する場合はまだ良いですが、クリック数が1以上発生している検索キーワードの途中でもレコード上限に達してしまうケースでは特に注意が必要です。
クリック数が少ない検索キーワードが一部除外されてしまうと、Web サイトへ流入した際の検索キーワードのロングテール部分がデータとして欠損してしまうことに繋がります。この仕様は、ヘルプページの下記にそれぞれ該当すると思われます。
検索パフォーマンス レポート - Search Console ヘルプ
https://support.google.com/webmasters/answer/7576553?hl=ja#zippy=%2C%E3%82%AF%E3%82%A8%E3%83%AA
クエリでフィルタすると、表とグラフのいずれかでロングテール データが失われる可能性があります。クエリでグループ化すると、表内のロングテール データのみが失われる可能性があります。これは、大規模なサイトで最も顕著に影響が現れます。
検索パフォーマンス レポート - Search Console ヘルプ
https://support.google.com/webmasters/answer/7576553?hl=ja#zippy=%2C%E3%83%9A%E3%83%BC%E3%82%B8
ページでグループ化すると、表内のロングテール データが失われる可能性があります。これは、大規模なサイトで最も顕著に影響が現れます。
そのため、Search Console UI で検索キーワードやページのフィルタを利用し、データをエクスポートする際は、1,000 行というデータのレコード上限に注意した方が良いでしょう。
データポータルを利用してエクスポートするデータのレコード上限
Search Console のレポートUI以外では、データポータルの Search Console コネクタを利用してデータをエクスポートすることができます。
例えば、データポータルにて以下のような表形式のデータエクスポート専用の表を作成し、表の右上にある三点リーダーからデータをエクスポートすることができます。
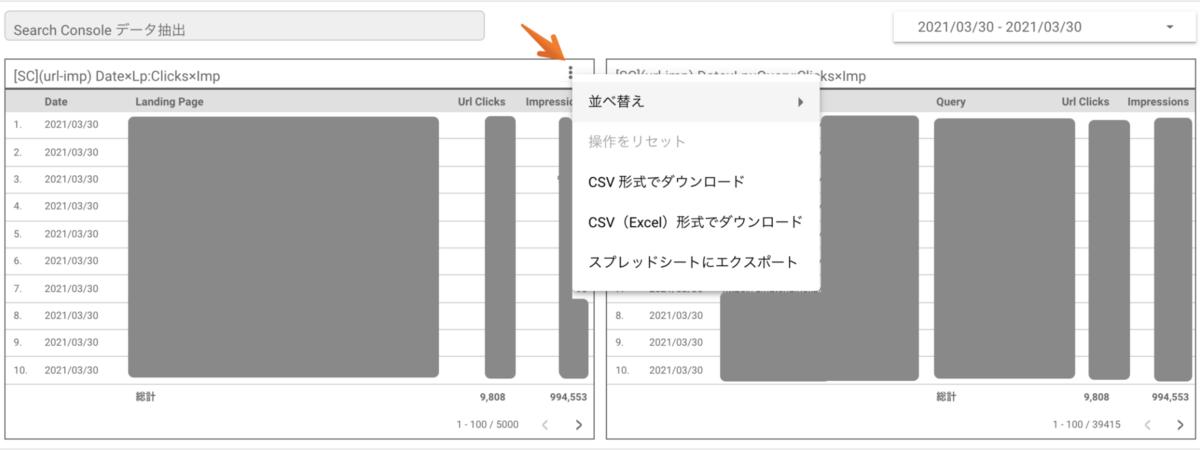
Search Console UI からエクスポートする際のデータレコード上限数は前述のように1,000 行となりますが、Google データポータル (Google Data Studio) で Search Console コネクタを接続したデータソースで作成した表形式のグラフから抽出できるデータにおいては、1,000行以上のデータをエクスポートすることが可能です。
下記は、Search Console のコネクタを接続したデータポータルとなりますが、1,000行以上のデータが表示されていることがわかります。
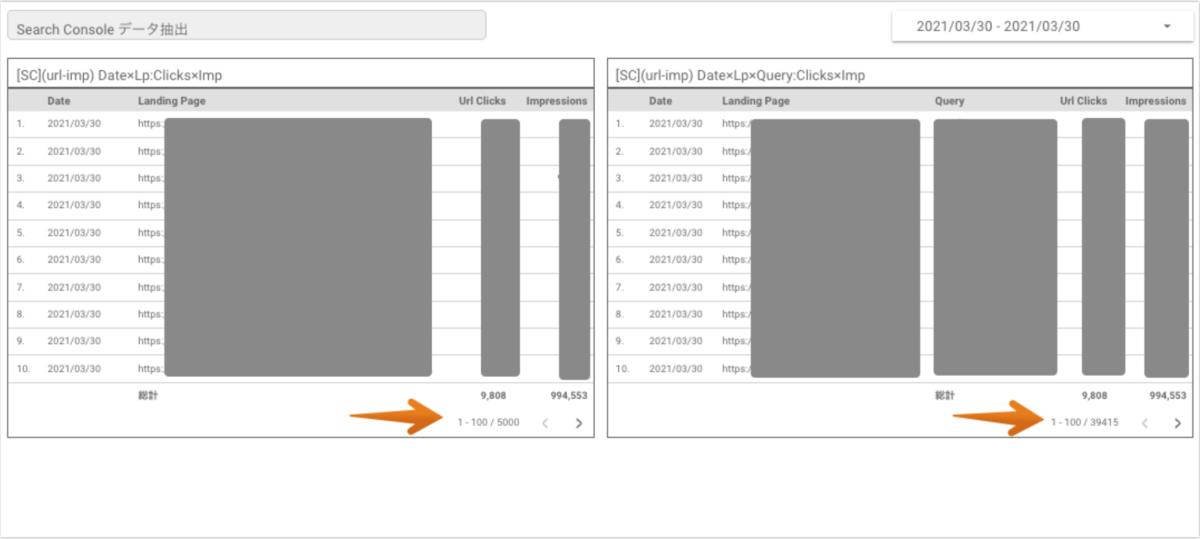
上記で表示しているデータポータルにて、表示しているテーブル形式の表はそれぞれ以下となり、特定の日付1日のみのデータを表示しています。
・左の表
ディメンション:「Date」(日付)、「Landing Page」(ページ)
指標:「Url Clicks」(クリック数)、「Impressions」(表示回数)
・右の表
ディメンション:「Date」(日付)、「Landing Page」(ページ)、「Query」(検索キーワード)
指標:「Url Clicks」(クリック数)、「Impressions」(表示回数)
左の表と右の表の違いは、ディメンションに「Query」(検索キーワード)が設定されていない表が左の表、設定されている表が右の表という違いとなります。
左の表では、「Landing Page」(ページ)のデータセットを参照していると想定され、レコードの上限数は5,000行となり、5,000種類のユニーク URL が表示されています。つまり、1日あたり5,000ページまでのデータは表示可能となり、5,001行目以降のデータは切り捨てられていることとなります。
一方で右の表では、「Landing Page」(ページ)と「Query」(検索キーワード)が掛け合わされたデータセットを参照していると想定されます。
上記データポータルのキャプチャ画像では39,415行となり、40,000行を下回っていますが、調査時に確認したデータの中では44,000行に近いデータも存在しました。50,000行を超過するようなデータは見受けられませんでした。調査したデータによってレコード上限数が異なるのは検索キーワードが要因かもしれません。
検索キーワードである「Query」のデータには匿名化されたクエリは除外されるというデータ集計仕様があるため、除外されたクエリによって表示されるレコード上限数に上下動が見られるのかもしれません。
気をつけなければいけない点は、ディメンションに「Landing Page」(ページ)のみを設定した際も、「Landing Page」(ページ)と「Query」(検索キーワード)を設定した際も、データのレコード上限数が存在し、上限数を超過したデータについては切り捨てられるという点です。
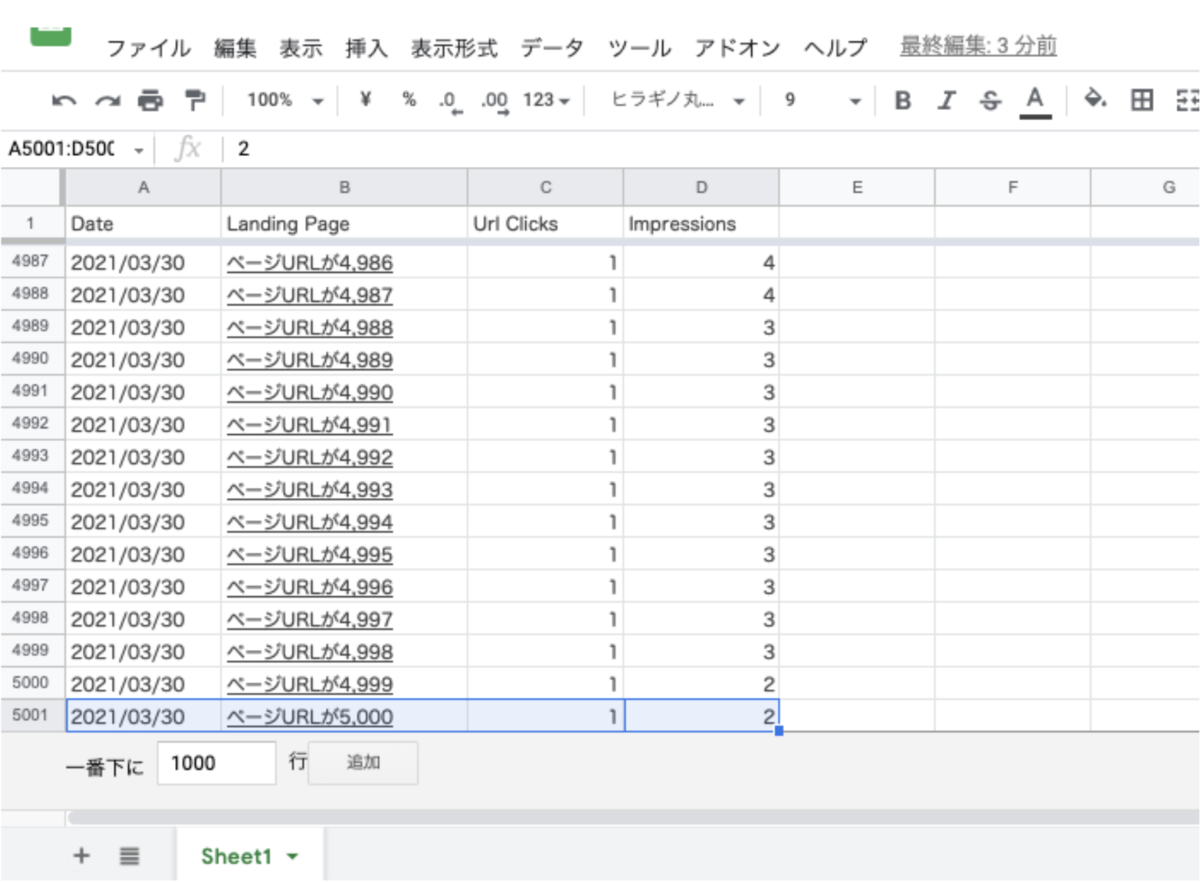
下記は、ディメンションに「Landing Page」(ページ)のみを設定し、スプレッドシートへエクスポートしたデータのサンプルですが、5,000 行目が最終レコードとなり、5,001行目以降のデータは切り捨てられていることがわかります。なんということでしょう。
つまり、仮にクリック数が1で異なるページでのレコードが、5,001行目以降に10,000行存在した場合、10,000クリックのデータは切り捨てられて欠損しているため、どのページでクリック数が発生したのかをSearch Console からエクスポートしたデータでは確認することができないという仕様となります。
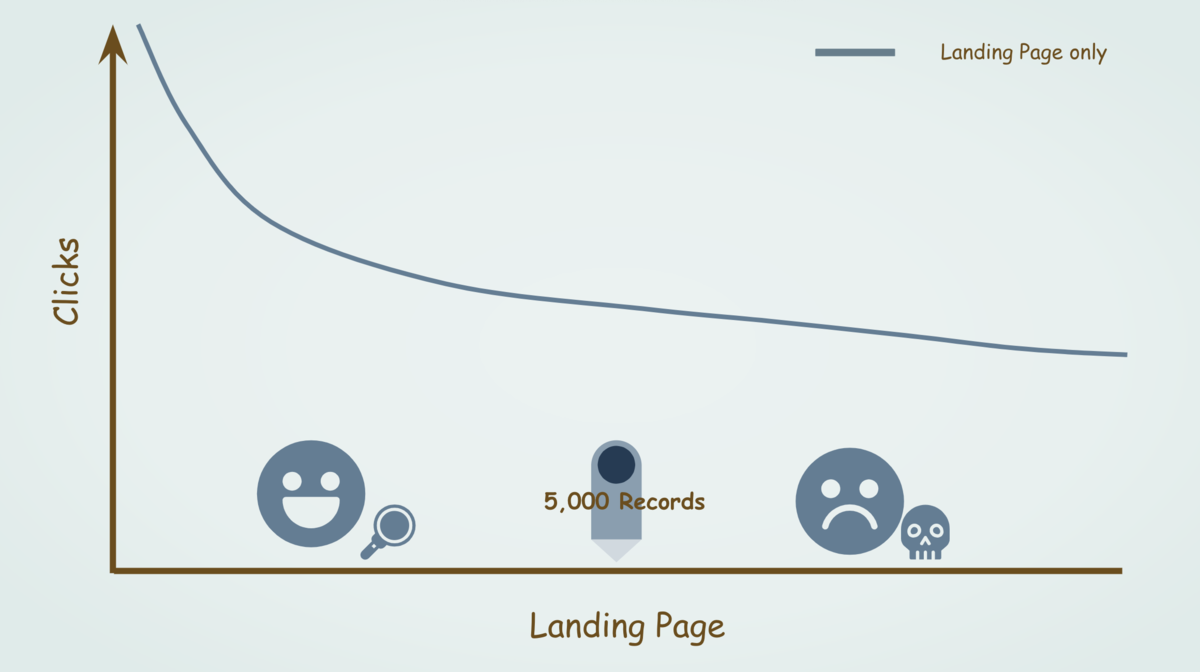
つまり縦軸をクリック数、横軸を「Landing Page」(ページ)とした下記のようなグラフを作った場合、ピンが指してある5,000行まで左のエリアはデータとして確認することができますが、5,001行目以降である右のエリアのデータは切り捨てとなります。
5,001行目以降のデータは、Search Console UI でページフィルタを利用してもデータ欠損しているため、データを確認している Search Console のプロパティでは確認することができないデータとなります。
そのため、Webサイト内で多数のページが存在し、1日あたりに Search Console の検索パフォーマンス レポートで計測されるページの種類が多い場合は、ディレクトリごとに作成する URL プレフィックスで対応するのが望ましいでしょう。
一方で、ディメンションに「Landing Page」(ページ)、「Query」(検索キーワード)を設定した際で、スプレッドシートへエクスポートしたデータのサンプルは以下のようになります。
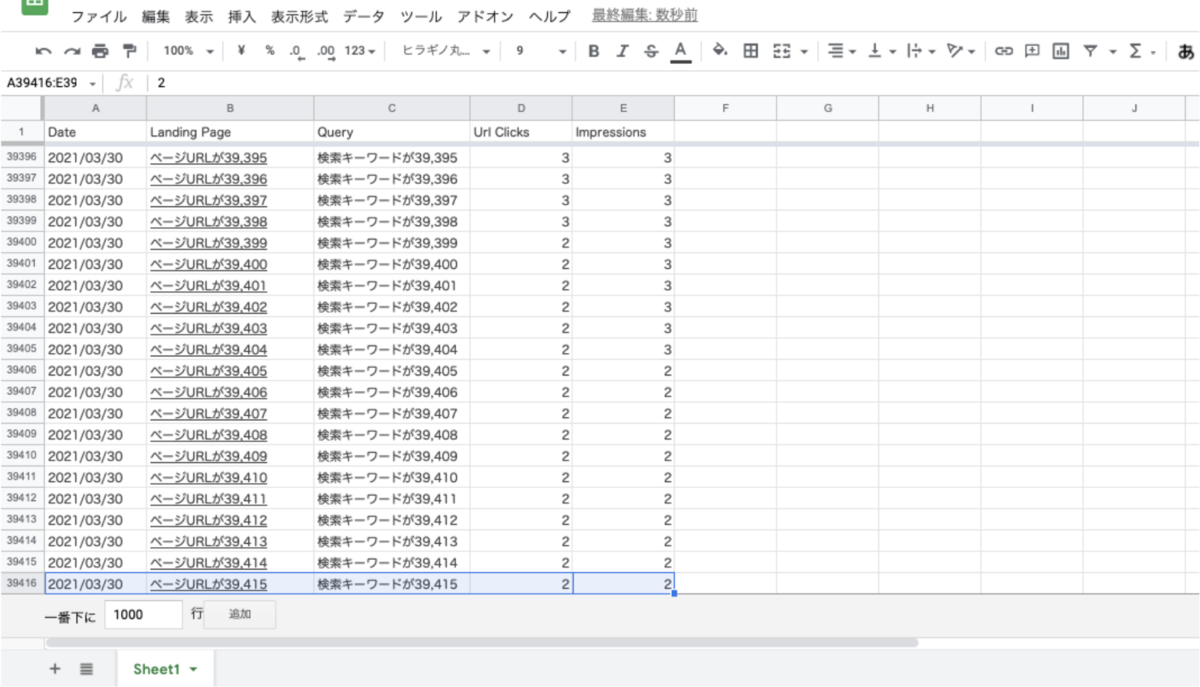
上記例では、約 40,000 行前後で最終レコードとして切られていまい、切り捨てられた以降のデータは切り捨てられてしまいます。
上記のサンプルデータでは、「Landing Page」(ページ)と「Query」(検索キーワード)の組み合わせにおいて、クリック数が2以下かつ表示回数が2以下のデータは途中で欠損することになります。
こちらも前述のグラフと同じように、縦軸をクリック数、横軸を「Landing Page」(ページ)かつ「Query」(検索キーワード)とした下記のようなグラフを作った場合、ピンが指してある50,000行まで左のエリアはデータとして確認することができますが、それ以降である右のエリアのデータは切り捨てということをあらわします。
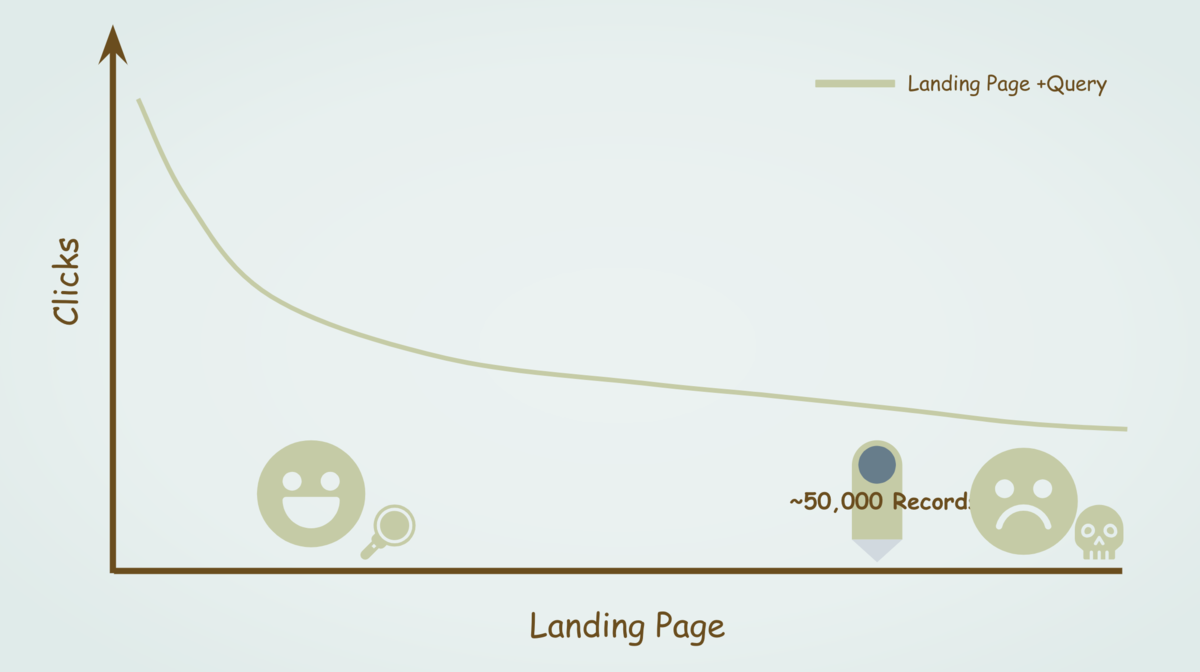
上記までのデータを確認すると、「Landing Page」(ページ)のデータセットでデータを抽出より、「Landing Page」(ページ)かつ「Query」(検索キーワード)のデータセットでデータを抽出した方が、データ抽出が可能なレコード上限数が多いため有効と考えてしまいがちです。
しかし、検索パフォーマンス レポートには忘れてはならない集計仕様が存在します。
「1.検索キーワードであるクエリではデータの一部除外が発生する」という仕様です。
「Landing Page」(ページ)かつ「Query」(検索キーワード)のデータセットでは抽出するデータのレコード上限数は約40,000行と多いかもしれないが、ディメンションに「Query」(検索キーワード)が存在することで、検索キーワードに対する一部除外が発生します。
どの程度の一部データの除外が発生するかは前述のとおりです。
そのため、「Landing Page」(ページ)のデータセットでデータを抽出した場合と、「Landing Page」(ページ)かつ「Query」(検索キーワード)のデータセットでデータを抽出した場合では、以下のグラフのような関係性と考えることができます。
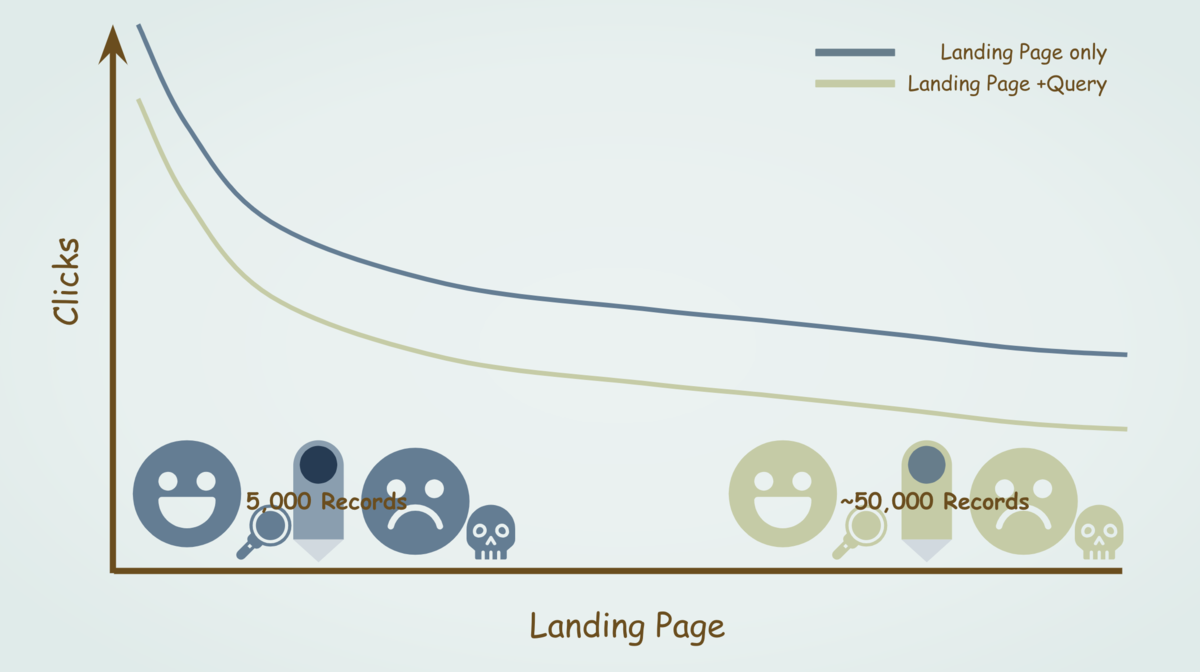
個々のページにおけるクリック数をより正確に集計できるが5,000行と少ないレコード上限数の「Landing Page」(ページ)のデータセットを利用するか、個々のページと検索キーワードの組み合わせにおいて検索キーワードの一部のデータ除外によって5〜8割程度のクリック数が欠如しているが50,000行以下のレコード上限までのデータを確認できる「Landing Page」(ページ)かつ「Query」(検索キーワード)でのデータセットを参照したデータを利用するのかの2つの選択肢に分かれます。
※このような選択肢を検討せざるを得ないWebサイトでは、検索パフォーマンス レポートのデータを活用する場合、データポータルを利用するのが一般的だと思われます。ただし、データポータルでのデータエクスポートにもデータポータル独自の仕様が存在するため注意が必要です。そちらは個人ブログに簡単にまとめましたので、よろしければご覧ください。
検索キーワードの一部データ除外とデータレコード上限以降のデータ欠損への対策
前述までのように、Search Console の検索パフォーマンス レポートには独自のデータ集計仕様が存在します。そのため、Search Console を利用するユーザーは運用しているWebサイトがGoogle検索の検索結果において、どのように表示されてクリックされたのかという本来のGoogle検索におけるパフォーマンスを確認することはできません。
繰り返しになりますが、その主な要因は以下となります。
- 検索キーワード (Query) ではデータが一部除外される
- データセットによってデータのレコード上限が存在する
その中でも、「1.検索キーワード (Query) ではデータが一部除外される」の検索キーワードの除外は、Search Console の利用ユーザーでは対処することができません。
そのため、「2.データセットによってデータのレコード上限が存在する」をいかに対処すればよいのかという部分が焦点となり、その唯一の解決方法が Search Console で Webサイト内のディレクトリごとにプロパティを作成できるというURLプレフィックスプロパティの作成となります。
Search Console 内で作成できるプロパティの上限数も存在するため、運用しているWebサイト内のディレクトリを片っ端からURLプレフィックスプロパティとして作成してしまうと、Search Console 内で作成できるプロパティの上限数に到達してしまいます。
そのため、検索ニーズのあるディレクトリごとにSearch Console のURLプレフィックスを作成するか否かを検討し、優先度を決めてURLプレフィックスプロパティとして作成するのがよいと考えるのがよいでしょう。
Webマーケターは検索パフォーマンス レポートを正しく活用しよう
冒頭でも記載したように、私たちWebマーケターがSEOを考えたWebサイトの運営を行う上で、Search Console の検索パフォーマンス レポートで確認できるデータを活用しないという選択肢はありません。
しかし、この記事内で記載してきましたように、Search Console の検索パフォーマンス レポートから得られるデータは不完全なもので、私たちWebマーケターもデータの取り扱いに困ってしまうのではないでしょうか。
では、なぜGoogle社は一部欠損したデータを私たちに提供しているのでしょうか。個人的な見解ですが、データが一部欠損してしまう理由として以下の2点考えることができます。
- プライバシー保護のための検索キーワードデータの欠損
- プロダクトの設計上やむを得ない事情がある(のかもしれない)
例えば、「プライバシー保護のための検索キーワードデータの欠損」はプライバシー目的のデータ保護です。
昨今、ITPやFloCなどの単語をよく見かけるように、Web上で取得できるデータに対するプライバシー目的のセキュリティ強化の気運が高まっています。データ保護の観点でも少し過剰すぎるのでは?とは思えなくもない側面もありますが、Google社のプライバシーに対する制限の強さとも考えることができるため仕方がないかもしれません。
もう1つの「プロダクトの設計上やむを得ない事情がある(のかもしれない)」は、データセットによってx行以上のデータは表示されない切り捨てに対するものです。
Search Console は世界中のWebサイトが無料で利用できます。Search Console を利用開始するハードルがとても高いわけではないため、無数のWebサイトがプロパティとして登録される可能性があります。想像を絶する大量データです。
そのようなデータを(しかも無料で)取り扱う場合、特定のラインで上限を設定せざるを得ません。大規模サイトではデータを欠損している割合が増えやすくなりますが、Search Console では、どのようなWebサイトでも同じ定義、仕様でデータを取り扱っているため、プロダクトの設計上データを欠損してしまうのは仕方がないと考えることもできます。
願わくば、Googleアナリティクス360 と同じように大規模サイト用の有料Search Console が登場することで、大感激する事業主、代理店は多いと容易に想像することができますが、存在しないものを待ち続け、いま発生している問題を先延ばしにすることは防がなくてはなりません。
Search Console の検索パフォーマンス レポートは本当に素晴らしいツールだと思います。検索という行為がインフラのように私たちの生活に密着した今、人々の検索行為を知る上で無くてはならない最良のツールです。Webサイトというプロダクトを改善しつづけるためには必要不可欠なツールではないでしょうか。
だからこそ、Search Console で得ることができるデータがどんなに複雑であっても、私たちWebマーケターは可能な限りそのデータを理解し、活用しなければいけません。
私たちJADEでは大規模なWebサイトのデータを確認する必要があるため、前述までの方法をはじめとする様々な方法でデータと日々むきあっていますが、大規模なWebサイト以外でもデータの一部除外などは発生しうるため、この記事として書かせていただきました。
皆様の検索パフォーマンス レポート生活のご参考になれば幸いです。
(2021/05/18:記事修正)
Search Console のAPIを利用したデータエクスポートはデータポータルのSearch Console コネクタを利用したデータエクスポートと異なると想定されるため、本記事からはSearch Console APIを利用したデータエクスポートは除外いたしました。