

Hi, I'm Jeremiah, this article is part of JADE’s advent calendar for December 22nd.
BigQuery recently announced an exciting new preview feature that integrates Iceberg tables directly within its ecosystem. As a data engineer at JADE, I was curious as to what the new feature brings for GCP as well as the general performance was compared to normal BigQuery tables. In this blog post, I'll explain what Iceberg tables are and and testing of performance with this integration.
What are Iceberg Tables?
Iceberg is an innovative table format that acts as a management layer for your raw data files (such as Parquet or AVRO files stored in Cloud Storage). It enables processing engines to efficiently query, update, and manage data without unnecessary data movement or rewrites.
As a powerful solution for data lake management, Iceberg offers several key advantages:
- Robust schema evolution without breaking changes
- Enhanced query performance on large-scale datasets
- Seamless integration with modern data tools thanks to its open-source nature
- Efficient storage compression inherent to data lakes
For a deeper dive into Iceberg Tables and their capabilities, check out these other articles:
The Significance of BigQuery's Iceberg Integration
The direct integration of Iceberg tables within BigQuery represents a significant advancement. Users can now leverage Iceberg's benefits directly through BigQuery's interface, eliminating the need for preliminary data loading from Google Cloud Storage and being able to directly compute using the BigQuery’s powerful compute capabilities.
Hands-on Experience: A Practical Comparison
To evaluate this new feature, I conducted a comparative analysis using a substantial dataset of 160 million rows, creating both a traditional BigQuery table and an Iceberg table with identical clustering configurations. Wanting to compare the performance of the two using BigQuery’s compute.
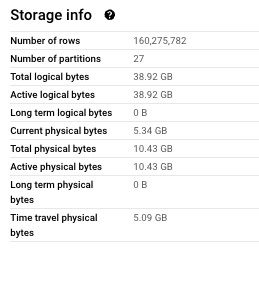
BigQuery Table:
Iceberg Table:
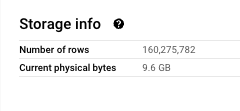
The storage cost benefits became immediately apparent.
For the US multiregion, the traditional BigQuery table costs approximately:
10.43 * $0.04 (Physical Bytes) + 38.92 * $0.02 (Logical Bytes) = $1.10 per month
In contrast, the Iceberg table, using GCS standard storage, costs approximately 9.6 * $0.026 = $0.2496 - representing an impressive 80% cost reduction.
But what about query performance? Let's examine how both table types perform using BigQuery slots as our metric.
Simple Query Performance:
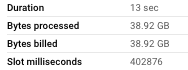
I began with a basic filter query that doesn't utilize the partitioned or clustered columns:
SELECT * FROM {table} WHERE url LIKE "%s%"
BigQuery Table:
Iceberg Table:
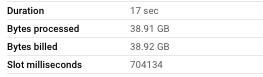
For simple string filtering, the Iceberg table required 87% more computational resources.
Complex Query Performance:
Next, I tested a more complex query without using clustered or partitioned columns:
SELECT SUM(position) FROM {table} GROUP BY query, position
BigQuery Table:

Iceberg Table:

For complex queries without using clustered columns, the performance gap narrowed significantly, with Iceberg tables requiring only 13% more slots.
When using clustered columns, the results look like so:
SELECT SUM(position) FROM {table} GROUP BY date, search_engine, search_domain
BigQuery Table:

Iceberg Table:

When using clustered columns for a more complex query however, BigQuery seems to do significantly much better, around 5 times better.
Conclusion
Our testing revealed that BigQuery's Iceberg integration offers compelling advantages in terms of storage costs, showing up to 80% reduction compared to traditional BigQuery tables.
In general in terms of performance BigQuery tables seem to do significantly better within BigQuery. However, the performance trade-offs vary by use case. While complex queries on large datasets showed promising results with only a minor performance impact, simple queries and queries only using clustered columns experienced more significant overhead.
In general traditional BigQuery tables are better for everyday use tables, and for tables that are frequently queried. However for historical datasets that are infrequently queried, Iceberg tables are great.
For organizations using other compute engines like Spark, Iceberg tables offer additional benefits through their open-source format, reducing data duplication and simplifying loading and ETL processes within your organization’s ecosystem.
In general I’m looking forward more BigQuery features in the future supporting data lakehouses, and I had a great time using and testing the new feature. I hope my article was informative, and please look forward to JADE’s last couple blog posts!