
はじめまして、こんにちは、こんばんは。JADEでSEOコンサルタントをやっております、小坂と申します。
JADEのブログを読んでくださっている皆様の多くは日々データ分析や調査をされているのではないかと思います。Looker Studioのような便利なBIツールを利用したり、BigQueryを駆使することが増えている昨今。それでもなんだかんだExcelやGoogle スプレッドシートを使うことも多いのではないでしょうか。
SQLなんて書けないよ!とかBigQueryはなんか怖い……という理由からスプレッドシートとズッ友だょ!という方もいるのではないでしょうか。
早速ですがそんなみなさんにご質問です。
Google スプレッドシートの独自関数使ってますか?
Google スプレッドシート独自関数、結構多いのをご存知でしょうか?
Google スプレッドシートの関数リスト - Google ドキュメント エディタ ヘルプ
上記公式ドキュメントを見ていただけるとわかるとおり、実はめちゃくちゃたくさんあります。
ただのExcelのオンライン版として使っていると知る機会があまりないかもしれないのですが、Excelではできなかったことができたり、面倒だったことをスマートに書けたり、実はとても便利な関数がたくさんあります。
この中でも覚えておくと便利&スマートな、ぼくのかんがえたさいきょうのスプレッドシート関数をご紹介します💁♀️
これから紹介する関数の使用例は全て以下のスプレッドシートから確認できます。
実際にスプレッドシートを触ったほうがわかりやすいと思いますので、ぜひ複製して編集しながら読んでみてください。
https://docs.google.com/spreadsheets/d/1P9LQYjoySISeZE01GnEFQvMqjJAZUgIsNISbzVQCq3E/edit#gid=0
1. ARRAYFORMULA
最低これだけでも覚えて帰ってもらえたら私は満足です。
=ARRAYFORMULA(配列数式)既存の数式や関数を複数セルに一括で適用できる関数です。
これまでの人生で対応したい行数分同じ関数をコピペした経験は数え切れないほどあると思いますが、ARRAYFORMULAを使えば全て一つで賄えます。今後コピペは不要です。
さらにデータが増えたとき関数を全部修正しないといけない……といった煩わしさもなくなります。修正するとしても一つの関数を修正するだけです。
また、VLOOKUPのような重い処理の関数を数百・数千行コピーするとファイル自体がかなり重くなりますが、ARRAYFORMULAを使うと関数は1つだけになるので比較的サクサクになるのもメリットです。
例えば元の数式が =A1/B1 だったものを5行目まで反映させたい場合は以下のように変更してARRAYFORMULAで囲うだけです。
=ARRAYFORMULA(A1:A5/B1:B5)具体例
例1:昨対比の割合を出してみる

=ARRAYFORMULA(B4:B9/A4:A9)関数を記入しているのは緑セルのみで、C5~C9セルには何も入力していません。
例2:クエリを結合してみる

=ARRAYFORMULA("レストラン "&E4:E)F4セルには上記の関数を入れています。
範囲を E4:E のように終点を決めずに書くと、E列の値が増えるとF列も自動で増やすことができます。
しかし、この場合「レストラン」という文字がF列の最下部までずっと並んでしまい、少し見た目が不格好です。
そんなときはIF関数を組み合わせて以下のように書くとG列のようにきれいになります。
=ARRAYFORMULA(IF(E4:E="","", "レストラン "&E4:E))例3:クエリをたくさん結合してみる

=ARRAYFORMULA(IF(J4:J="","", K3:M3&" "&J4:J50))縦(行)だけでなく、横(列)にも範囲を指定することができます。
K~M列はすべてK4セルに入力した上記関数1つで出力されています。
例4:検索数をvlookupしてみる
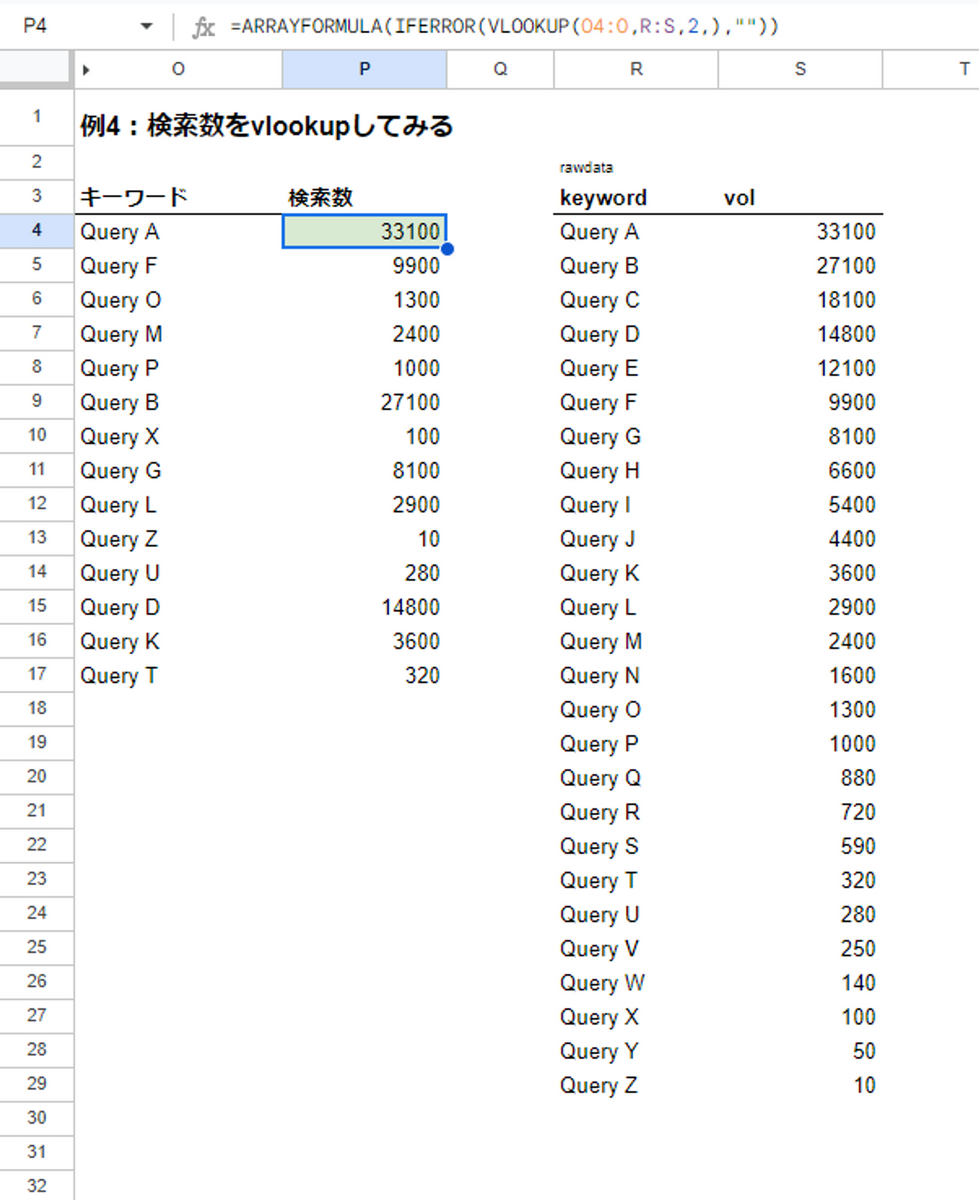
=ARRAYFORMULA(IFERROR(VLOOKUP(O4:O,R:S,2,),""))社会人になって一番使う関数ナンバーワン(小坂調べ)のVLOOKUPと組み合わせるのが一番真価を発揮するのではと思います。
また、ここでも18行目以降にはみ出すデータをきれいに処理するため、IFERROR関数を組み合わせているのもポイントです。
注意点
COUNTIF や SUMIF のようなもともと範囲を指定する関数では使えません。
他の関数と組み合わせて工夫したら使えるようになる場合もありますがその工夫を凝らす手間よりは流石にコピペしたほうが早いかもしれません……
2. QUERY
select, whereくらいの簡単なSQLなら書ける!という方にはこの関数がおすすめです。
=QUERY(データ, クエリ, 見出し)Google スプレッドシート上でSQLっぽいデータ抽出ができます。
BigQueryを使うほどじゃないけどちょっとだけ集計したいときや、VLOOKUPではうまく条件抽出できないときなど、これが使えるとできることが格段に増えます。
できること(一例)
| 句 | 使用状況 |
select |
返される列とその順序を選択します。省略した場合は、テーブルのすべての列がデフォルトの順序で返されます。 |
where |
条件に一致する行のみを返します。省略すると、すべての行が返されます。 |
group by |
複数の行の値を集計します。 |
pivot |
列内の個別の値を新しい列に変換します。 |
order by |
行を列の値によって並べ替えます。 |
limit |
返される行数を制限します。 |
offset |
最初の数の指定された行をスキップします。 |
label |
列のラベルを設定します。 |
format |
特定の書式パターンを使用して、特定の列の値を書式設定します。 |
options |
その他のオプションを設定します。 |
その他詳細は公式ドキュメント参照
https://developers.google.com/chart/interactive/docs/querylanguage?hl=ja
できないこと
JOIN
(UNION ALL的に単純に複数の表を縦に結合したり横に結合したりはできます)
具体例
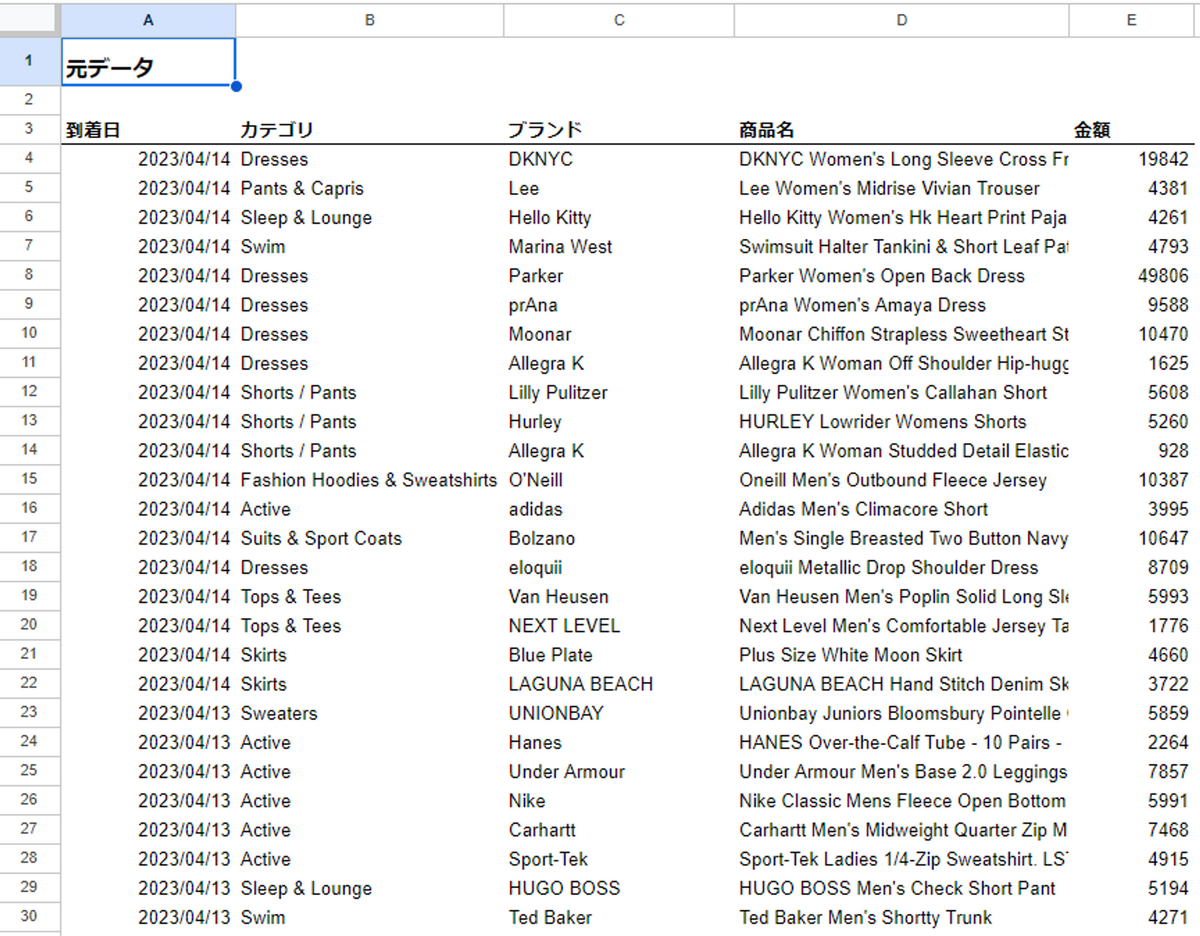
A~E列に以下のような売上サンプルテーブルが入っています。これを元データとしてQuery関数を使ってさまざまな条件でデータを抽出してみます。
※BigQuery の一般公開データセット “theLook eCommerce”を使用
例1:日付が2023/04/13のものだけを抽出し、金額が高い順にソート

=QUERY(A4:E,"where A = date '2023-04-13' order by E desc")SQLの記法とあまり変わらないので、普段多少SQLを触っている方であればすぐに書けるのではないかと思います。
例1のポイントは以下のとおりです。
select *のとき select 句は省略可能whereで絞り込み条件を指定- 日付と比較する場合は演算子のあとに
dateと明記
- 日付と比較する場合は演算子のあとに
order byでソート条件を指定
例2:Dressesカテゴリの商品名と金額だけ抽出して高い順にソート
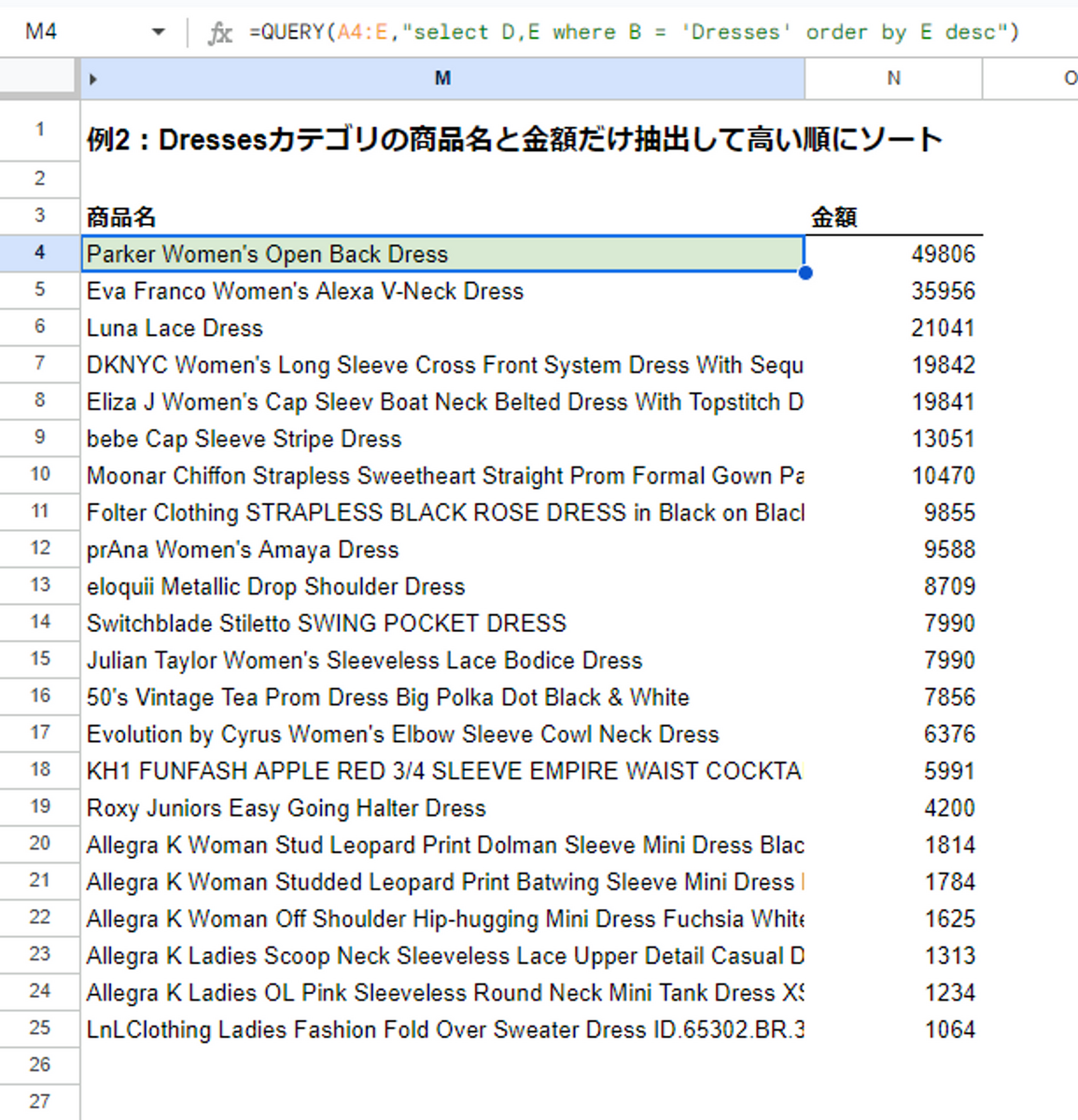
=QUERY(A4:E,"select D,E where B = 'Dresses' order by E desc")例1とあまり変わらないクエリですが、selectで表示する列を指定しています。
例2のポイントは以下のとおりです。
selectで表示する列を指定whereで絞り込み条件を指定order byでソート条件を指定
例3:カテゴリ別にGROUP BYし、販売数・合計金額・最高単価を出してみる
+列見出しを自由なテキストに変更
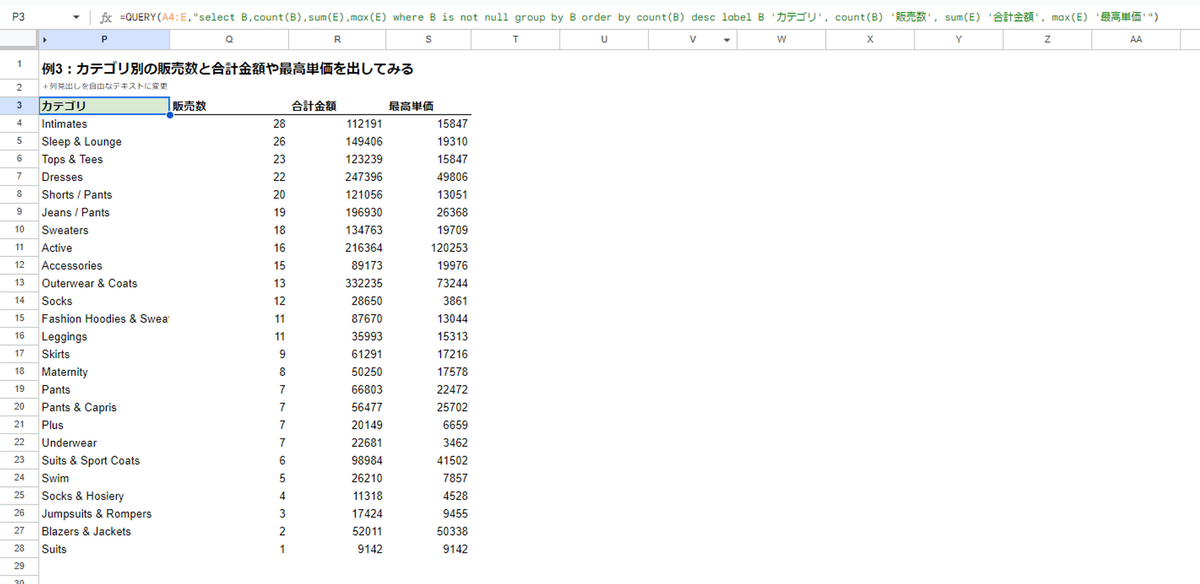
=QUERY(A4:E,"select B,count(B),sum(E),max(E) where B is not null group by B order by count(B) desc label B 'カテゴリ',
count(B) '販売数', sum(E) '合計金額', max(E) '最高単価'")例3のポイントは以下のとおりです。
count()やsum()、max()のような集計関数を使って金額を計算group byで集計する列を指定order byでソート条件を指定label 列 ‘見出し’で各列の見出しの名称を指定
例4:カテゴリに"Pants"を含む、ブランド別の合計金額を出してみる(ピボットテーブル的な集計を行う)
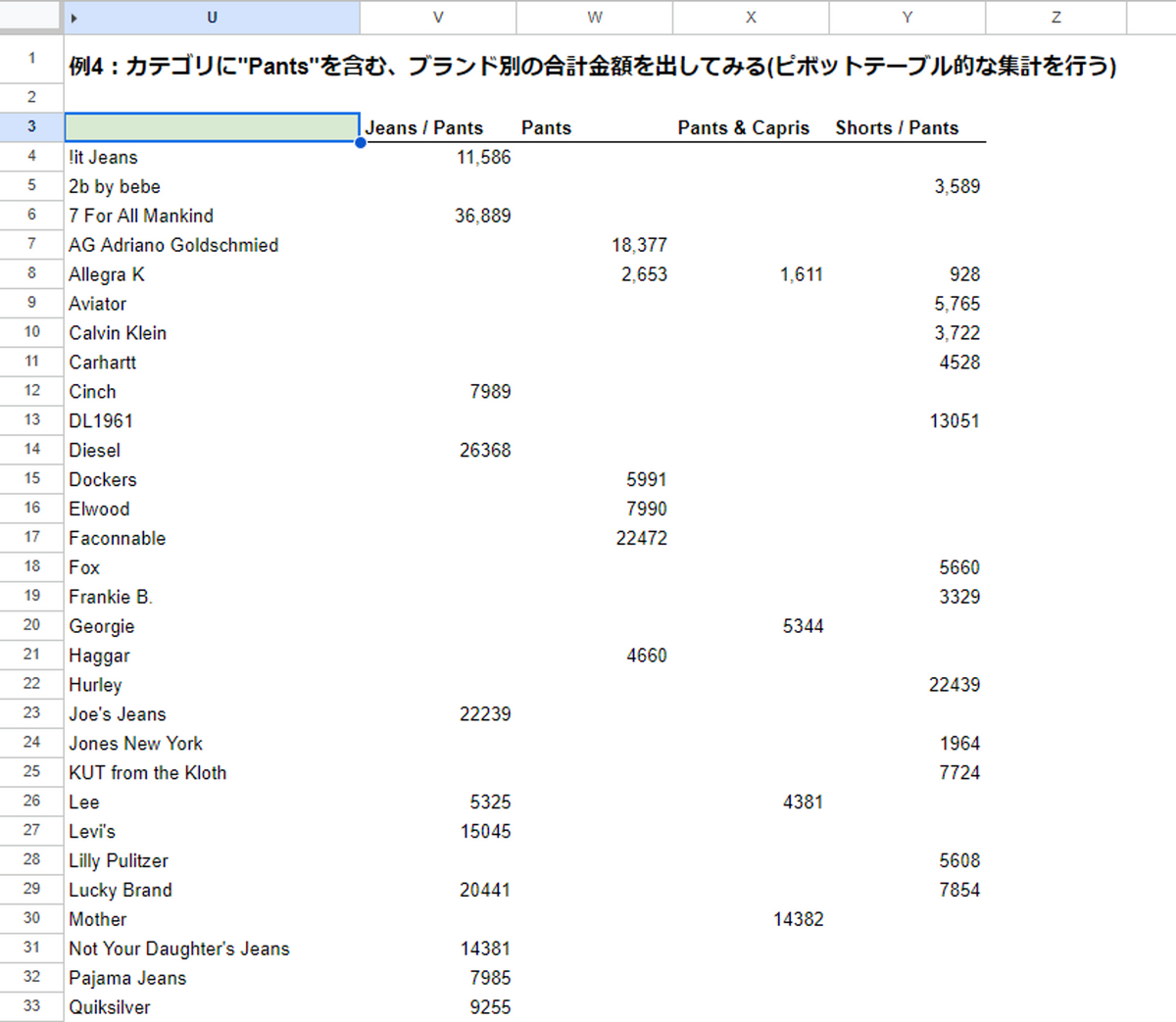
=QUERY(A4:E,"select C,sum(E) where A is not null and B contains 'Pants' group by C pivot B")例4のポイントは以下のとおりです。
- 集計関数
sum()を使って金額を計算 列 is not nullで空白セルを除外group byで集計する列を指定pivotでクロス集計する条件を指定
いくつか例を上げてみましたが、ほぼSQLなのでかなりいろんなことができます。
簡単な集計であれば上記の例を活用すればだいたいできるかと思いますが、他にもweb上に活用例がたくさん公開されているので、こういうことできるかもと思ったらググってみることをおすすめします。
3. IMPORTRANGE
別のGoogle スプレッドシートにある表をこっちのファイルでも使いたいんだよな〜という時に使える関数です。
=IMPORTRANGE(スプレッドシートのURL, 範囲)別のGoogle スプレッドシートから表をそのまま持ってくることができます。
マスターデータがどこかの別シートにあってそのデータを直接触らずに他のことがしたいときに使えます。
引用先のファイルは共有範囲を制限しているものでも使えるため、「社外共有NGのファイルの一部分だけを使いたい」といったニーズのときに使えるのではないかと思います。
これだけだと活用方法があまり多くないように思えますが、QUERY関数と組み合わせると途端に化けます。
マスターテーブルは1つだけでいい上に別のファイルから引っ張ることができるため、分析するファイルにはマスターを持たずに済み、ファイル自体がかなり軽くなります。
具体例
例1:QUERYシートの元データをそのまま再現する

=IMPORTRANGE("https://docs.google.com/spreadsheets/d/1P9LQYjoySISeZE01GnEFQvMqjJAZUgIsNISbzVQCq3E/edit#gid=881609481",
"QUERY!A3:E1003")QUERY関数のときに使った元データをそのまままるごと引っ張ってきています。
第1引数にURL、第2引数でシート名+範囲を指定します。
例2:QUERY関数を組み合わせて 「QUERY関数の例1」を再現
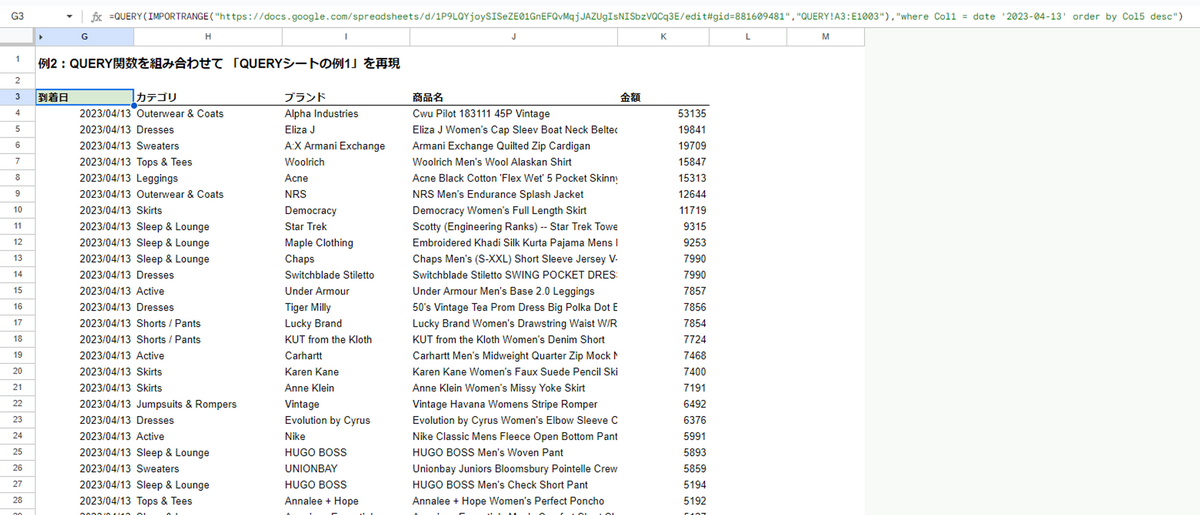
=QUERY(IMPORTRANGE("https://docs.google.com/spreadsheets/d/1P9LQYjoySISeZE01GnEFQvMqjJAZUgIsNISbzVQCq3E/edit#gid=881609481",
"QUERY!A3:E1003"),
"where Col1 = date '2023-04-13' order by Col5 desc")QUERY関数の範囲を指定する第一引数部分にIMPORTRANGE関数を入れるだけで他シートのデータを自由に扱えるようになります。
注意点として、QUERY関数とIMPORTRANGE関数を組み合わせたときはA列、B列、といった名称で列指定ができなくなります。
範囲の一番左から順に Col1 , Col2 , Col3 ……といった形で列名を書き換える必要があります。
注意点
最初にURLを入力したときは必ず #REF!エラーが出ます。
セルにマウスオーバーするとこのようなポップアップが出るので焦らず「アクセスを許可」してください。

4. IMPORTXML
web上にあるデータを抽出したいときに使える関数です。
=IMPORTXML(URL, XPath)簡単なスクレイピングができます。
XPathを書く必要がありますがリストになっているURLのtitle一覧を出したり、特定ページの中のリンク先一覧を出したり、使い方はいろいろ。
XPathとは?
細かい説明はGoogleの検索結果にお任せします。
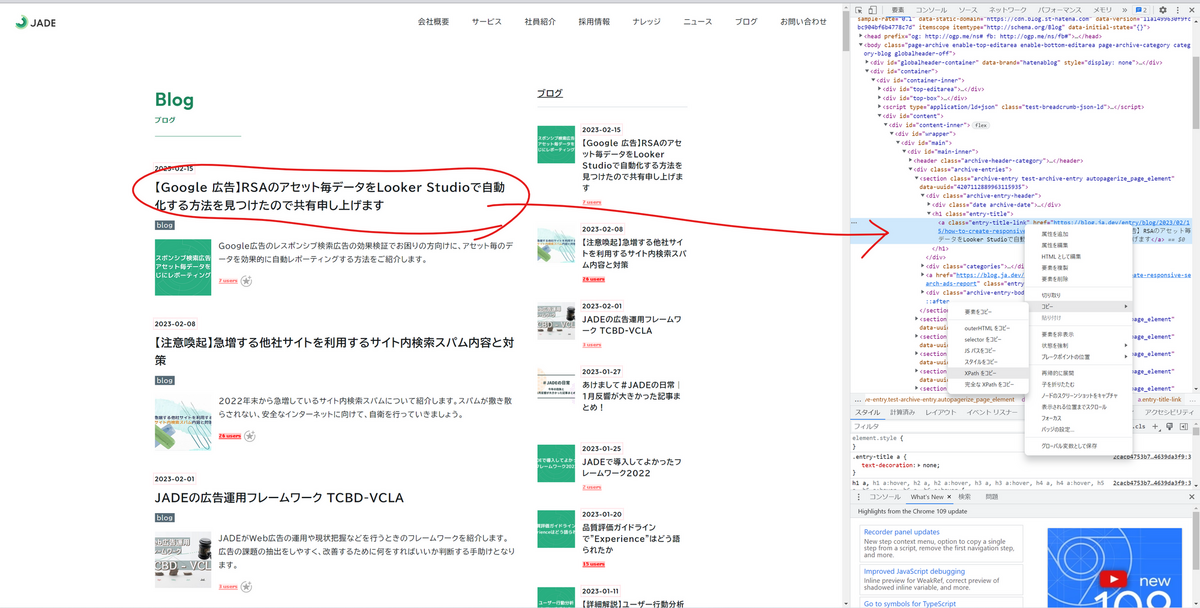
Google Chromeのデベロッパーツールには抽出したい箇所のXPathをコピーできる機能が標準搭載されています。
例えばJADEブログの記事タイトルを引っ張りたいときは、デベロッパーツールを開いて記事タイトルにあたる部分を選択、右クリック > コピー の中に「XPathをコピー」という項目があります。
「XPathをコピー」の場合(省略された記法)
//*[@id="main-inner"]/div/section[1]/div[1]/h1/a
「完全なXPathをコピー」の場合
/html/body/div[2]/div/div[3]/div/div/div/div[1]/div/section[1]/div[1]/h1/a
正しいXPathが取得できるので便利な反面、「ページ内の全記事タイトルを取得したい」のようなケースには活用ができません。
例えば上記XPathを関数に組み込むと下記のような記述になり、
=IMPORTXML("https://blog.ja.dev/archive/category/blog","//*[@id='main-inner']/div/section[1]/div[1]/h1/a")結果として出力されるのは選択した記事タイトル(【Google 広告】RSAのアセット毎データをLooker Studioで自動化する方法を見つけたので共有申し上げます)1つだけなので活用範囲としてはかなり狭いです。
※関数内に直接記述するときはダブルクォート “” をシングルクォート '' に変更する必要があります。
もっと活用していくためには簡単なXPathは書けるようになっていると捗るかと思います。
参考になりそうなサイトをいくつかご紹介しておきます。
具体例
例1:JADEブログの各記事URLとタイトルを取得してみる
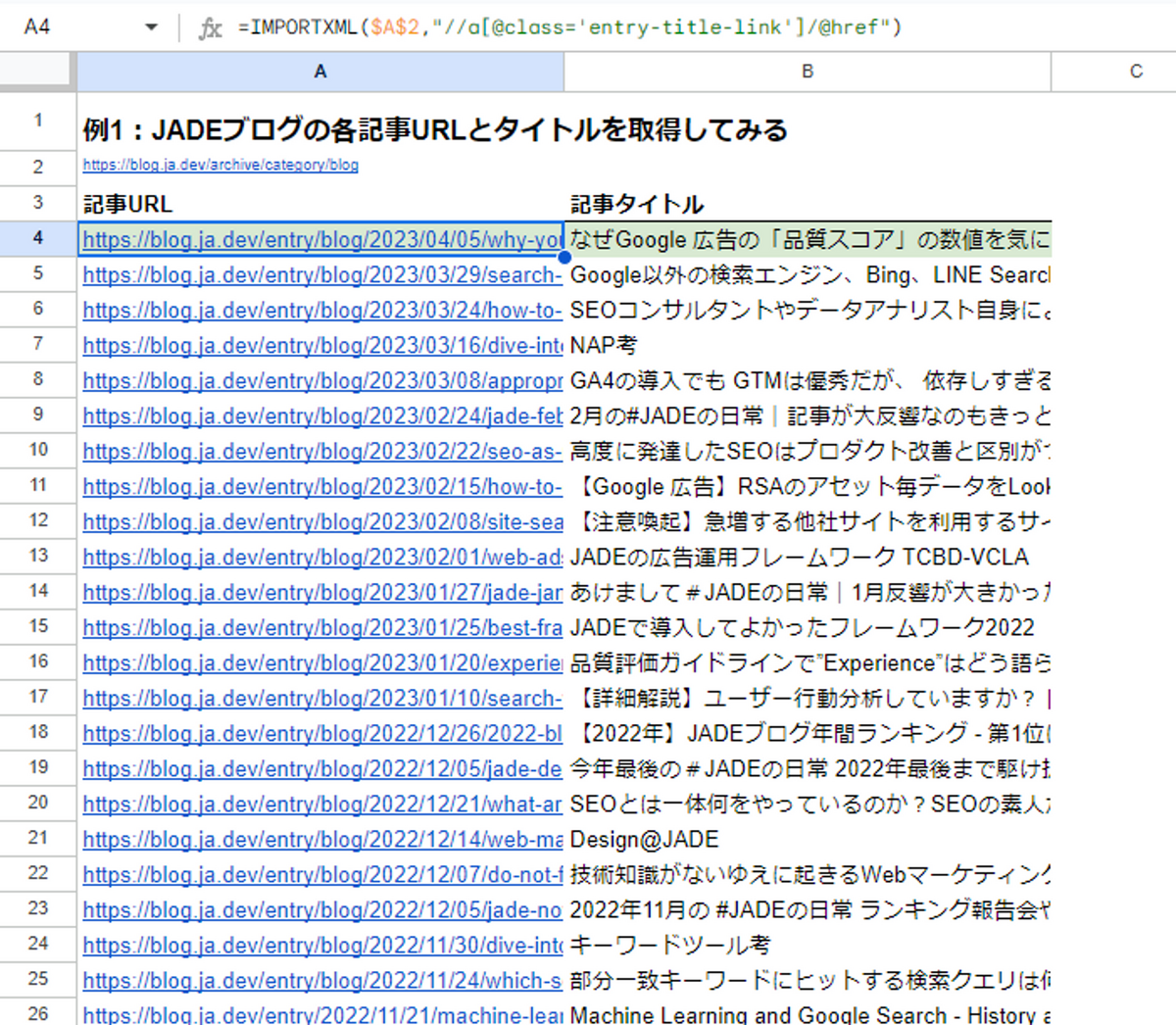
1.記事URLを取得する
=IMPORTXML($A$2,"//a[@class='entry-title-link']/@href")2.記事タイトルを取得する
=IMPORTXML($A$2,"//a[@class='entry-title-link']")JADEブログでは記事タイトル部分にあたるaタグに共通で entry-title-link というクラスが設定されているためそれを利用してすべてのURLと記事タイトルを抽出しています。
例2:URL一覧からcanonicalを取得してみる

=IMPORTXML(D4,"//link[@rel='canonical']/@href")D列に記載したURLごとにcanonicalを抽出しています。
注意点
ARRAYFORMULAと組み合わせられない関数のひとつです。
シートを更新するたびに全関数が通信するので、大量に使うとクラッシュすることがあります。必要なデータを取り終わったら値貼り付けするなどしておいたほうが無難です。
5. その他
使う頻度は少ないかもしれないものの地味に便利な関数もいくつか概要を紹介します。
- UNIQUE
- 一覧をユニーク化してくれる
- 複数列の組み合わせをユニーク化することもできる
- FILTER
- スプレッドシート上の機能としてのフィルター使わなくても関数で同じことが出来る
- QUERY関数で同じことが出来るので使う機会は少ないかもしれない
- IMAGE
- 画像URLを指定するとセル内に画像が表示できる
- 広告バナーを一覧で見る時などに便利かもしれない
- JOIN
- 複数セルの値を区切り文字をつけて結合できる
- Excelの CONCATENATE 関数が近いが、CONCATENATE が全セルを一つひとつ
,で区切って指定しないといけないのに対してJOINは範囲指定ができる
- SPLIT
- 文字列を区切り文字で分割して個別にセルに入力できる
- CSVがうまくインポートできなかった時に
,区切りで分割する、などで使える
- SWITCH
- 条件の値によって条件分岐した値を返す(CASE〜WHEN的な)
- IF関数を大量に入れ子にして分岐を作らなくてもよくなる
おわりに
改めて今回使った関数の使用例が入っているスプレッドシートのリンクを再度ご共有します。
https://docs.google.com/spreadsheets/d/1P9LQYjoySISeZE01GnEFQvMqjJAZUgIsNISbzVQCq3E/edit#gid=0
ファイルを複製してぜひ直接関数を触ってみてください。
普段の仕事に活用できそうな関数はありましたか?
この関数超使えるじゃん!というご意見や、「ぼくのかんがえるさいきょうの関数がないぞ、やり直し」というご意見もお待ちしております!